# Text-to-SQL
> [!NOTE]
> Code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/text_to_sql); based on work by [LlamaIndex](https://docs.llamaindex.ai/en/stable/examples/workflow/advanced_text_to_sql/).
Data analytics drives modern decision-making, but SQL often creates a bottleneck. Writing queries requires technical expertise, so non-technical stakeholders must rely on data teams. That translation layer slows everyone down.
Text-to-SQL narrows this gap by turning natural language into executable SQL queries. It lowers the barrier to structured data and makes databases accessible to more people.
In this tutorial, we build a Text-to-SQL workflow using LlamaIndex and evaluate it on the [WikiTableQuestions dataset](https://ppasupat.github.io/WikiTableQuestions/) (a benchmark of natural language questions over semi-structured tables). We then explore prompt optimization to see whether it improves accuracy and show how to track prompts and results over time. Along the way, we'll see what worked, what didn't, and what we learned about building durable evaluation pipelines. The pattern here can be adapted to your own datasets and workflows.
## Ingesting data
We start by ingesting the WikiTableQuestions dataset, which comes as CSV files, into a SQLite database. This database serves as the source of truth for our Text-to-SQL pipeline.
```
import asyncio
import fnmatch
import os
import re
import zipfile
import flyte
import pandas as pd
import requests
from flyte.io import Dir, File
from llama_index.core.llms import ChatMessage
from llama_index.core.prompts import ChatPromptTemplate
from llama_index.llms.openai import OpenAI
from pydantic import BaseModel, Field
from sqlalchemy import Column, Integer, MetaData, String, Table, create_engine
from utils import env
# {{docs-fragment table_info}}
class TableInfo(BaseModel):
"""Information regarding a structured table."""
table_name: str = Field(..., description="table name (underscores only, no spaces)")
table_summary: str = Field(
..., description="short, concise summary/caption of the table"
)
# {{/docs-fragment table_info}}
@env.task
async def download_and_extract(zip_path: str, search_glob: str) -> Dir:
"""Download and extract the dataset zip file if not already available."""
output_zip = "data.zip"
extract_dir = "wiki_table_questions"
if not os.path.exists(zip_path):
response = requests.get(zip_path, stream=True)
with open(output_zip, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
else:
output_zip = zip_path
print(f"Using existing file {output_zip}")
os.makedirs(extract_dir, exist_ok=True)
with zipfile.ZipFile(output_zip, "r") as zip_ref:
for member in zip_ref.namelist():
if fnmatch.fnmatch(member, search_glob):
zip_ref.extract(member, extract_dir)
remote_dir = await Dir.from_local(extract_dir)
return remote_dir
async def read_csv_file(
csv_file: File, nrows: int | None = None
) -> pd.DataFrame | None:
"""Safely download and parse a CSV file into a DataFrame."""
try:
local_csv_file = await csv_file.download()
return pd.read_csv(local_csv_file, nrows=nrows)
except Exception as e:
print(f"Error parsing {csv_file.path}: {e}")
return None
def sanitize_column_name(col_name: str) -> str:
"""Sanitize column names by replacing spaces/special chars with underscores."""
return re.sub(r"\W+", "_", col_name)
async def create_table_from_dataframe(
df: pd.DataFrame, table_name: str, engine, metadata_obj
):
"""Create a SQL table from a Pandas DataFrame."""
# Sanitize column names
sanitized_columns = {col: sanitize_column_name(col) for col in df.columns}
df = df.rename(columns=sanitized_columns)
# Define table columns based on DataFrame dtypes
columns = [
Column(col, String if dtype == "object" else Integer)
for col, dtype in zip(df.columns, df.dtypes)
]
table = Table(table_name, metadata_obj, *columns)
# Create table in database
metadata_obj.create_all(engine)
# Insert data into table
with engine.begin() as conn:
for _, row in df.iterrows():
conn.execute(table.insert().values(**row.to_dict()))
@flyte.trace
async def create_table(
csv_file: File, table_info: TableInfo, database_path: str
) -> str:
"""Safely create a table from CSV if parsing succeeds."""
df = await read_csv_file(csv_file)
if df is None:
return "false"
print(f"Creating table: {table_info.table_name}")
engine = create_engine(f"sqlite:///{database_path}")
metadata_obj = MetaData()
await create_table_from_dataframe(df, table_info.table_name, engine, metadata_obj)
return "true"
@flyte.trace
async def llm_structured_predict(
df_str: str,
table_names: list[str],
prompt_tmpl: ChatPromptTemplate,
feedback: str,
llm: OpenAI,
) -> TableInfo:
return llm.structured_predict(
TableInfo,
prompt_tmpl,
feedback=feedback,
table_str=df_str,
exclude_table_name_list=str(list(table_names)),
)
async def generate_unique_table_info(
df_str: str,
table_names: list[str],
prompt_tmpl: ChatPromptTemplate,
llm: OpenAI,
tablename_lock: asyncio.Lock,
retries: int = 3,
) -> TableInfo | None:
"""Process a single CSV file to generate a unique TableInfo."""
last_table_name = None
for attempt in range(retries):
feedback = ""
if attempt > 0:
feedback = f"Note: '{last_table_name}' already exists. Please pick a new name not in {table_names}."
table_info = await llm_structured_predict(
df_str, table_names, prompt_tmpl, feedback, llm
)
last_table_name = table_info.table_name
async with tablename_lock:
if table_info.table_name not in table_names:
table_names.append(table_info.table_name)
return table_info
print(f"Table name {table_info.table_name} already exists, retrying...")
return None
async def process_csv_file(
csv_file: File,
table_names: list[str],
semaphore: asyncio.Semaphore,
tablename_lock: asyncio.Lock,
llm: OpenAI,
prompt_tmpl: ChatPromptTemplate,
) -> TableInfo | None:
"""Process a single CSV file to generate a unique TableInfo."""
async with semaphore:
df = await read_csv_file(csv_file, nrows=10)
if df is None:
return None
return await generate_unique_table_info(
df.to_csv(), table_names, prompt_tmpl, llm, tablename_lock
)
@env.task
async def extract_table_info(
data_dir: Dir, model: str, concurrency: int
) -> list[TableInfo | None]:
"""Extract structured table information from CSV files."""
table_names: list[str] = []
semaphore = asyncio.Semaphore(concurrency)
tablename_lock = asyncio.Lock()
llm = OpenAI(model=model)
prompt_str = """\
Provide a JSON object with the following fields:
- `table_name`: must be unique and descriptive (underscores only, no generic names).
- `table_summary`: short and concise summary of the table.
Do NOT use any of these table names: {exclude_table_name_list}
Table:
{table_str}
{feedback}
"""
prompt_tmpl = ChatPromptTemplate(
message_templates=[ChatMessage.from_str(prompt_str, role="user")]
)
tasks = [
process_csv_file(
csv_file, table_names, semaphore, tablename_lock, llm, prompt_tmpl
)
async for csv_file in data_dir.walk()
]
return await asyncio.gather(*tasks)
# {{docs-fragment data_ingestion}}
@env.task
async def data_ingestion(
csv_zip_path: str = "https://github.com/ppasupat/WikiTableQuestions/releases/download/v1.0.2/WikiTableQuestions-1.0.2-compact.zip",
search_glob: str = "WikiTableQuestions/csv/200-csv/*.csv",
concurrency: int = 5,
model: str = "gpt-4o-mini",
) -> tuple[File, list[TableInfo | None]]:
"""Main data ingestion pipeline: download → extract → analyze → create DB."""
data_dir = await download_and_extract(csv_zip_path, search_glob)
table_infos = await extract_table_info(data_dir, model, concurrency)
database_path = "wiki_table_questions.db"
i = 0
async for csv_file in data_dir.walk():
table_info = table_infos[i]
if table_info:
ok = await create_table(csv_file, table_info, database_path)
if ok == "false":
table_infos[i] = None
else:
print(f"Skipping table creation for {csv_file} due to missing TableInfo.")
i += 1
db_file = await File.from_local(database_path)
return db_file, table_infos
# {{/docs-fragment data_ingestion}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/data_ingestion.py*
The ingestion step:
1. Downloads the dataset (a zip archive from GitHub).
2. Extracts the CSV files locally.
3. Generates table metadata (names and descriptions).
4. Creates corresponding tables in SQLite.
The Flyte task returns both the path to the database and the generated table metadata.
```
import asyncio
import fnmatch
import os
import re
import zipfile
import flyte
import pandas as pd
import requests
from flyte.io import Dir, File
from llama_index.core.llms import ChatMessage
from llama_index.core.prompts import ChatPromptTemplate
from llama_index.llms.openai import OpenAI
from pydantic import BaseModel, Field
from sqlalchemy import Column, Integer, MetaData, String, Table, create_engine
from utils import env
# {{docs-fragment table_info}}
class TableInfo(BaseModel):
"""Information regarding a structured table."""
table_name: str = Field(..., description="table name (underscores only, no spaces)")
table_summary: str = Field(
..., description="short, concise summary/caption of the table"
)
# {{/docs-fragment table_info}}
@env.task
async def download_and_extract(zip_path: str, search_glob: str) -> Dir:
"""Download and extract the dataset zip file if not already available."""
output_zip = "data.zip"
extract_dir = "wiki_table_questions"
if not os.path.exists(zip_path):
response = requests.get(zip_path, stream=True)
with open(output_zip, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
else:
output_zip = zip_path
print(f"Using existing file {output_zip}")
os.makedirs(extract_dir, exist_ok=True)
with zipfile.ZipFile(output_zip, "r") as zip_ref:
for member in zip_ref.namelist():
if fnmatch.fnmatch(member, search_glob):
zip_ref.extract(member, extract_dir)
remote_dir = await Dir.from_local(extract_dir)
return remote_dir
async def read_csv_file(
csv_file: File, nrows: int | None = None
) -> pd.DataFrame | None:
"""Safely download and parse a CSV file into a DataFrame."""
try:
local_csv_file = await csv_file.download()
return pd.read_csv(local_csv_file, nrows=nrows)
except Exception as e:
print(f"Error parsing {csv_file.path}: {e}")
return None
def sanitize_column_name(col_name: str) -> str:
"""Sanitize column names by replacing spaces/special chars with underscores."""
return re.sub(r"\W+", "_", col_name)
async def create_table_from_dataframe(
df: pd.DataFrame, table_name: str, engine, metadata_obj
):
"""Create a SQL table from a Pandas DataFrame."""
# Sanitize column names
sanitized_columns = {col: sanitize_column_name(col) for col in df.columns}
df = df.rename(columns=sanitized_columns)
# Define table columns based on DataFrame dtypes
columns = [
Column(col, String if dtype == "object" else Integer)
for col, dtype in zip(df.columns, df.dtypes)
]
table = Table(table_name, metadata_obj, *columns)
# Create table in database
metadata_obj.create_all(engine)
# Insert data into table
with engine.begin() as conn:
for _, row in df.iterrows():
conn.execute(table.insert().values(**row.to_dict()))
@flyte.trace
async def create_table(
csv_file: File, table_info: TableInfo, database_path: str
) -> str:
"""Safely create a table from CSV if parsing succeeds."""
df = await read_csv_file(csv_file)
if df is None:
return "false"
print(f"Creating table: {table_info.table_name}")
engine = create_engine(f"sqlite:///{database_path}")
metadata_obj = MetaData()
await create_table_from_dataframe(df, table_info.table_name, engine, metadata_obj)
return "true"
@flyte.trace
async def llm_structured_predict(
df_str: str,
table_names: list[str],
prompt_tmpl: ChatPromptTemplate,
feedback: str,
llm: OpenAI,
) -> TableInfo:
return llm.structured_predict(
TableInfo,
prompt_tmpl,
feedback=feedback,
table_str=df_str,
exclude_table_name_list=str(list(table_names)),
)
async def generate_unique_table_info(
df_str: str,
table_names: list[str],
prompt_tmpl: ChatPromptTemplate,
llm: OpenAI,
tablename_lock: asyncio.Lock,
retries: int = 3,
) -> TableInfo | None:
"""Process a single CSV file to generate a unique TableInfo."""
last_table_name = None
for attempt in range(retries):
feedback = ""
if attempt > 0:
feedback = f"Note: '{last_table_name}' already exists. Please pick a new name not in {table_names}."
table_info = await llm_structured_predict(
df_str, table_names, prompt_tmpl, feedback, llm
)
last_table_name = table_info.table_name
async with tablename_lock:
if table_info.table_name not in table_names:
table_names.append(table_info.table_name)
return table_info
print(f"Table name {table_info.table_name} already exists, retrying...")
return None
async def process_csv_file(
csv_file: File,
table_names: list[str],
semaphore: asyncio.Semaphore,
tablename_lock: asyncio.Lock,
llm: OpenAI,
prompt_tmpl: ChatPromptTemplate,
) -> TableInfo | None:
"""Process a single CSV file to generate a unique TableInfo."""
async with semaphore:
df = await read_csv_file(csv_file, nrows=10)
if df is None:
return None
return await generate_unique_table_info(
df.to_csv(), table_names, prompt_tmpl, llm, tablename_lock
)
@env.task
async def extract_table_info(
data_dir: Dir, model: str, concurrency: int
) -> list[TableInfo | None]:
"""Extract structured table information from CSV files."""
table_names: list[str] = []
semaphore = asyncio.Semaphore(concurrency)
tablename_lock = asyncio.Lock()
llm = OpenAI(model=model)
prompt_str = """\
Provide a JSON object with the following fields:
- `table_name`: must be unique and descriptive (underscores only, no generic names).
- `table_summary`: short and concise summary of the table.
Do NOT use any of these table names: {exclude_table_name_list}
Table:
{table_str}
{feedback}
"""
prompt_tmpl = ChatPromptTemplate(
message_templates=[ChatMessage.from_str(prompt_str, role="user")]
)
tasks = [
process_csv_file(
csv_file, table_names, semaphore, tablename_lock, llm, prompt_tmpl
)
async for csv_file in data_dir.walk()
]
return await asyncio.gather(*tasks)
# {{docs-fragment data_ingestion}}
@env.task
async def data_ingestion(
csv_zip_path: str = "https://github.com/ppasupat/WikiTableQuestions/releases/download/v1.0.2/WikiTableQuestions-1.0.2-compact.zip",
search_glob: str = "WikiTableQuestions/csv/200-csv/*.csv",
concurrency: int = 5,
model: str = "gpt-4o-mini",
) -> tuple[File, list[TableInfo | None]]:
"""Main data ingestion pipeline: download → extract → analyze → create DB."""
data_dir = await download_and_extract(csv_zip_path, search_glob)
table_infos = await extract_table_info(data_dir, model, concurrency)
database_path = "wiki_table_questions.db"
i = 0
async for csv_file in data_dir.walk():
table_info = table_infos[i]
if table_info:
ok = await create_table(csv_file, table_info, database_path)
if ok == "false":
table_infos[i] = None
else:
print(f"Skipping table creation for {csv_file} due to missing TableInfo.")
i += 1
db_file = await File.from_local(database_path)
return db_file, table_infos
# {{/docs-fragment data_ingestion}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/data_ingestion.py*
With Union artifacts (coming soon!), you'll be able to persist the ingested SQLite database as an artifact. This removes the need to rerun data ingestion in every pipeline.
## From question to SQL
Next, we define a workflow that converts natural language into executable SQL using a retrieval-augmented generation (RAG) approach.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "llama-index-core>=0.11.0",
# "llama-index-llms-openai>=0.2.0",
# "sqlalchemy>=2.0.0",
# "pandas>=2.0.0",
# "requests>=2.25.0",
# "pydantic>=2.0.0",
# ]
# main = "text_to_sql"
# params = ""
# ///
import asyncio
from pathlib import Path
import flyte
from data_ingestion import TableInfo, data_ingestion
from flyte.io import Dir, File
from llama_index.core import (
PromptTemplate,
SQLDatabase,
StorageContext,
VectorStoreIndex,
load_index_from_storage,
)
from llama_index.core.llms import ChatResponse
from llama_index.core.objects import ObjectIndex, SQLTableNodeMapping, SQLTableSchema
from llama_index.core.prompts.prompt_type import PromptType
from llama_index.core.retrievers import SQLRetriever
from llama_index.core.schema import TextNode
from llama_index.llms.openai import OpenAI
from sqlalchemy import create_engine, text
from utils import env
# {{docs-fragment index_tables}}
@flyte.trace
async def index_table(table_name: str, table_index_dir: str, database_uri: str) -> str:
"""Index a single table into vector store."""
path = f"{table_index_dir}/{table_name}"
engine = create_engine(database_uri)
def _fetch_rows():
with engine.connect() as conn:
cursor = conn.execute(text(f'SELECT * FROM "{table_name}"'))
return cursor.fetchall()
result = await asyncio.to_thread(_fetch_rows)
nodes = [TextNode(text=str(tuple(row))) for row in result]
index = VectorStoreIndex(nodes)
index.set_index_id("vector_index")
index.storage_context.persist(path)
return path
@env.task
async def index_all_tables(db_file: File) -> Dir:
"""Index all tables concurrently."""
table_index_dir = "table_indices"
Path(table_index_dir).mkdir(exist_ok=True)
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
tasks = [
index_table(t, table_index_dir, "sqlite:///local_db.sqlite")
for t in sql_database.get_usable_table_names()
]
await asyncio.gather(*tasks)
remote_dir = await Dir.from_local(table_index_dir)
return remote_dir
# {{/docs-fragment index_tables}}
@flyte.trace
async def get_table_schema_context(
table_schema_obj: SQLTableSchema,
database_uri: str,
) -> str:
"""Retrieve schema + optional description context for a single table."""
engine = create_engine(database_uri)
sql_database = SQLDatabase(engine)
table_info = sql_database.get_single_table_info(table_schema_obj.table_name)
if table_schema_obj.context_str:
table_info += f" The table description is: {table_schema_obj.context_str}"
return table_info
@flyte.trace
async def get_table_row_context(
table_schema_obj: SQLTableSchema,
local_vector_index_dir: str,
query: str,
) -> str:
"""Retrieve row-level context examples using vector search."""
storage_context = StorageContext.from_defaults(
persist_dir=str(f"{local_vector_index_dir}/{table_schema_obj.table_name}")
)
vector_index = load_index_from_storage(storage_context, index_id="vector_index")
vector_retriever = vector_index.as_retriever(similarity_top_k=2)
relevant_nodes = vector_retriever.retrieve(query)
if not relevant_nodes:
return ""
row_context = "\nHere are some relevant example rows (values in the same order as columns above)\n"
for node in relevant_nodes:
row_context += str(node.get_content()) + "\n"
return row_context
async def process_table(
table_schema_obj: SQLTableSchema,
database_uri: str,
local_vector_index_dir: str,
query: str,
) -> str:
"""Combine schema + row context for one table."""
table_info = await get_table_schema_context(table_schema_obj, database_uri)
row_context = await get_table_row_context(
table_schema_obj, local_vector_index_dir, query
)
full_context = table_info
if row_context:
full_context += "\n" + row_context
print(f"Table Info: {full_context}")
return full_context
async def get_table_context_and_rows_str(
query: str,
database_uri: str,
table_schema_objs: list[SQLTableSchema],
vector_index_dir: Dir,
):
"""Get combined schema + row context for all tables."""
local_vector_index_dir = await vector_index_dir.download()
# run per-table work concurrently
context_strs = await asyncio.gather(
*[
process_table(t, database_uri, local_vector_index_dir, query)
for t in table_schema_objs
]
)
return "\n\n".join(context_strs)
# {{docs-fragment retrieve_tables}}
@env.task
async def retrieve_tables(
query: str,
table_infos: list[TableInfo | None],
db_file: File,
vector_index_dir: Dir,
) -> str:
"""Retrieve relevant tables and return schema context string."""
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
table_node_mapping = SQLTableNodeMapping(sql_database)
table_schema_objs = [
SQLTableSchema(table_name=t.table_name, context_str=t.table_summary)
for t in table_infos
if t is not None
]
obj_index = ObjectIndex.from_objects(
table_schema_objs,
table_node_mapping,
VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)
retrieved_schemas = obj_retriever.retrieve(query)
return await get_table_context_and_rows_str(
query, "sqlite:///local_db.sqlite", retrieved_schemas, vector_index_dir
)
# {{/docs-fragment retrieve_tables}}
def parse_response_to_sql(chat_response: ChatResponse) -> str:
"""Extract SQL query from LLM response."""
response = chat_response.message.content
sql_query_start = response.find("SQLQuery:")
if sql_query_start != -1:
response = response[sql_query_start:]
if response.startswith("SQLQuery:"):
response = response[len("SQLQuery:") :]
sql_result_start = response.find("SQLResult:")
if sql_result_start != -1:
response = response[:sql_result_start]
return response.strip().strip("```").strip()
# {{docs-fragment sql_and_response}}
@env.task
async def generate_sql(query: str, table_context: str, model: str, prompt: str) -> str:
"""Generate SQL query from natural language question and table context."""
llm = OpenAI(model=model)
fmt_messages = (
PromptTemplate(
prompt,
prompt_type=PromptType.TEXT_TO_SQL,
)
.partial_format(dialect="sqlite")
.format_messages(query_str=query, schema=table_context)
)
chat_response = await llm.achat(fmt_messages)
return parse_response_to_sql(chat_response)
@env.task
async def generate_response(query: str, sql: str, db_file: File, model: str) -> str:
"""Run SQL query on database and synthesize final response."""
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
sql_retriever = SQLRetriever(sql_database)
retrieved_rows = sql_retriever.retrieve(sql)
response_synthesis_prompt = PromptTemplate(
"Given an input question, synthesize a response from the query results.\n"
"Query: {query_str}\n"
"SQL: {sql_query}\n"
"SQL Response: {context_str}\n"
"Response: "
)
llm = OpenAI(model=model)
fmt_messages = response_synthesis_prompt.format_messages(
sql_query=sql,
context_str=str(retrieved_rows),
query_str=query,
)
chat_response = await llm.achat(fmt_messages)
return chat_response.message.content
# {{/docs-fragment sql_and_response}}
# {{docs-fragment text_to_sql}}
@env.task
async def text_to_sql(
system_prompt: str = (
"Given an input question, first create a syntactically correct {dialect} "
"query to run, then look at the results of the query and return the answer. "
"You can order the results by a relevant column to return the most "
"interesting examples in the database.\n\n"
"Never query for all the columns from a specific table, only ask for a "
"few relevant columns given the question.\n\n"
"Pay attention to use only the column names that you can see in the schema "
"description. "
"Be careful to not query for columns that do not exist. "
"Pay attention to which column is in which table. "
"Also, qualify column names with the table name when needed. "
"You are required to use the following format, each taking one line:\n\n"
"Question: Question here\n"
"SQLQuery: SQL Query to run\n"
"SQLResult: Result of the SQLQuery\n"
"Answer: Final answer here\n\n"
"Only use tables listed below.\n"
"{schema}\n\n"
"Question: {query_str}\n"
"SQLQuery: "
),
query: str = "What was the year that The Notorious BIG was signed to Bad Boy?",
model: str = "gpt-4o-mini",
) -> str:
db_file, table_infos = await data_ingestion()
vector_index_dir = await index_all_tables(db_file)
table_context = await retrieve_tables(query, table_infos, db_file, vector_index_dir)
sql = await generate_sql(query, table_context, model, system_prompt)
return await generate_response(query, sql, db_file, model)
# {{/docs-fragment text_to_sql}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(text_to_sql)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/text_to_sql.py*
The main `text_to_sql` task orchestrates the pipeline:
- Ingest data
- Build vector indices for each table
- Retrieve relevant tables and rows
- Generate SQL queries with an LLM
- Execute queries and synthesize answers
We use OpenAI GPT models with carefully structured prompts to maximize SQL correctness.
### Vector indexing
We index each table's rows semantically so the model can retrieve relevant examples during SQL generation.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "llama-index-core>=0.11.0",
# "llama-index-llms-openai>=0.2.0",
# "sqlalchemy>=2.0.0",
# "pandas>=2.0.0",
# "requests>=2.25.0",
# "pydantic>=2.0.0",
# ]
# main = "text_to_sql"
# params = ""
# ///
import asyncio
from pathlib import Path
import flyte
from data_ingestion import TableInfo, data_ingestion
from flyte.io import Dir, File
from llama_index.core import (
PromptTemplate,
SQLDatabase,
StorageContext,
VectorStoreIndex,
load_index_from_storage,
)
from llama_index.core.llms import ChatResponse
from llama_index.core.objects import ObjectIndex, SQLTableNodeMapping, SQLTableSchema
from llama_index.core.prompts.prompt_type import PromptType
from llama_index.core.retrievers import SQLRetriever
from llama_index.core.schema import TextNode
from llama_index.llms.openai import OpenAI
from sqlalchemy import create_engine, text
from utils import env
# {{docs-fragment index_tables}}
@flyte.trace
async def index_table(table_name: str, table_index_dir: str, database_uri: str) -> str:
"""Index a single table into vector store."""
path = f"{table_index_dir}/{table_name}"
engine = create_engine(database_uri)
def _fetch_rows():
with engine.connect() as conn:
cursor = conn.execute(text(f'SELECT * FROM "{table_name}"'))
return cursor.fetchall()
result = await asyncio.to_thread(_fetch_rows)
nodes = [TextNode(text=str(tuple(row))) for row in result]
index = VectorStoreIndex(nodes)
index.set_index_id("vector_index")
index.storage_context.persist(path)
return path
@env.task
async def index_all_tables(db_file: File) -> Dir:
"""Index all tables concurrently."""
table_index_dir = "table_indices"
Path(table_index_dir).mkdir(exist_ok=True)
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
tasks = [
index_table(t, table_index_dir, "sqlite:///local_db.sqlite")
for t in sql_database.get_usable_table_names()
]
await asyncio.gather(*tasks)
remote_dir = await Dir.from_local(table_index_dir)
return remote_dir
# {{/docs-fragment index_tables}}
@flyte.trace
async def get_table_schema_context(
table_schema_obj: SQLTableSchema,
database_uri: str,
) -> str:
"""Retrieve schema + optional description context for a single table."""
engine = create_engine(database_uri)
sql_database = SQLDatabase(engine)
table_info = sql_database.get_single_table_info(table_schema_obj.table_name)
if table_schema_obj.context_str:
table_info += f" The table description is: {table_schema_obj.context_str}"
return table_info
@flyte.trace
async def get_table_row_context(
table_schema_obj: SQLTableSchema,
local_vector_index_dir: str,
query: str,
) -> str:
"""Retrieve row-level context examples using vector search."""
storage_context = StorageContext.from_defaults(
persist_dir=str(f"{local_vector_index_dir}/{table_schema_obj.table_name}")
)
vector_index = load_index_from_storage(storage_context, index_id="vector_index")
vector_retriever = vector_index.as_retriever(similarity_top_k=2)
relevant_nodes = vector_retriever.retrieve(query)
if not relevant_nodes:
return ""
row_context = "\nHere are some relevant example rows (values in the same order as columns above)\n"
for node in relevant_nodes:
row_context += str(node.get_content()) + "\n"
return row_context
async def process_table(
table_schema_obj: SQLTableSchema,
database_uri: str,
local_vector_index_dir: str,
query: str,
) -> str:
"""Combine schema + row context for one table."""
table_info = await get_table_schema_context(table_schema_obj, database_uri)
row_context = await get_table_row_context(
table_schema_obj, local_vector_index_dir, query
)
full_context = table_info
if row_context:
full_context += "\n" + row_context
print(f"Table Info: {full_context}")
return full_context
async def get_table_context_and_rows_str(
query: str,
database_uri: str,
table_schema_objs: list[SQLTableSchema],
vector_index_dir: Dir,
):
"""Get combined schema + row context for all tables."""
local_vector_index_dir = await vector_index_dir.download()
# run per-table work concurrently
context_strs = await asyncio.gather(
*[
process_table(t, database_uri, local_vector_index_dir, query)
for t in table_schema_objs
]
)
return "\n\n".join(context_strs)
# {{docs-fragment retrieve_tables}}
@env.task
async def retrieve_tables(
query: str,
table_infos: list[TableInfo | None],
db_file: File,
vector_index_dir: Dir,
) -> str:
"""Retrieve relevant tables and return schema context string."""
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
table_node_mapping = SQLTableNodeMapping(sql_database)
table_schema_objs = [
SQLTableSchema(table_name=t.table_name, context_str=t.table_summary)
for t in table_infos
if t is not None
]
obj_index = ObjectIndex.from_objects(
table_schema_objs,
table_node_mapping,
VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)
retrieved_schemas = obj_retriever.retrieve(query)
return await get_table_context_and_rows_str(
query, "sqlite:///local_db.sqlite", retrieved_schemas, vector_index_dir
)
# {{/docs-fragment retrieve_tables}}
def parse_response_to_sql(chat_response: ChatResponse) -> str:
"""Extract SQL query from LLM response."""
response = chat_response.message.content
sql_query_start = response.find("SQLQuery:")
if sql_query_start != -1:
response = response[sql_query_start:]
if response.startswith("SQLQuery:"):
response = response[len("SQLQuery:") :]
sql_result_start = response.find("SQLResult:")
if sql_result_start != -1:
response = response[:sql_result_start]
return response.strip().strip("```").strip()
# {{docs-fragment sql_and_response}}
@env.task
async def generate_sql(query: str, table_context: str, model: str, prompt: str) -> str:
"""Generate SQL query from natural language question and table context."""
llm = OpenAI(model=model)
fmt_messages = (
PromptTemplate(
prompt,
prompt_type=PromptType.TEXT_TO_SQL,
)
.partial_format(dialect="sqlite")
.format_messages(query_str=query, schema=table_context)
)
chat_response = await llm.achat(fmt_messages)
return parse_response_to_sql(chat_response)
@env.task
async def generate_response(query: str, sql: str, db_file: File, model: str) -> str:
"""Run SQL query on database and synthesize final response."""
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
sql_retriever = SQLRetriever(sql_database)
retrieved_rows = sql_retriever.retrieve(sql)
response_synthesis_prompt = PromptTemplate(
"Given an input question, synthesize a response from the query results.\n"
"Query: {query_str}\n"
"SQL: {sql_query}\n"
"SQL Response: {context_str}\n"
"Response: "
)
llm = OpenAI(model=model)
fmt_messages = response_synthesis_prompt.format_messages(
sql_query=sql,
context_str=str(retrieved_rows),
query_str=query,
)
chat_response = await llm.achat(fmt_messages)
return chat_response.message.content
# {{/docs-fragment sql_and_response}}
# {{docs-fragment text_to_sql}}
@env.task
async def text_to_sql(
system_prompt: str = (
"Given an input question, first create a syntactically correct {dialect} "
"query to run, then look at the results of the query and return the answer. "
"You can order the results by a relevant column to return the most "
"interesting examples in the database.\n\n"
"Never query for all the columns from a specific table, only ask for a "
"few relevant columns given the question.\n\n"
"Pay attention to use only the column names that you can see in the schema "
"description. "
"Be careful to not query for columns that do not exist. "
"Pay attention to which column is in which table. "
"Also, qualify column names with the table name when needed. "
"You are required to use the following format, each taking one line:\n\n"
"Question: Question here\n"
"SQLQuery: SQL Query to run\n"
"SQLResult: Result of the SQLQuery\n"
"Answer: Final answer here\n\n"
"Only use tables listed below.\n"
"{schema}\n\n"
"Question: {query_str}\n"
"SQLQuery: "
),
query: str = "What was the year that The Notorious BIG was signed to Bad Boy?",
model: str = "gpt-4o-mini",
) -> str:
db_file, table_infos = await data_ingestion()
vector_index_dir = await index_all_tables(db_file)
table_context = await retrieve_tables(query, table_infos, db_file, vector_index_dir)
sql = await generate_sql(query, table_context, model, system_prompt)
return await generate_response(query, sql, db_file, model)
# {{/docs-fragment text_to_sql}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(text_to_sql)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/text_to_sql.py*
Each row becomes a text node stored in LlamaIndex’s `VectorStoreIndex`. This lets the system pull semantically similar rows when handling queries.
### Table retrieval and context building
We then retrieve the most relevant tables for a given query and build rich context that combines schema information with sample rows.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "llama-index-core>=0.11.0",
# "llama-index-llms-openai>=0.2.0",
# "sqlalchemy>=2.0.0",
# "pandas>=2.0.0",
# "requests>=2.25.0",
# "pydantic>=2.0.0",
# ]
# main = "text_to_sql"
# params = ""
# ///
import asyncio
from pathlib import Path
import flyte
from data_ingestion import TableInfo, data_ingestion
from flyte.io import Dir, File
from llama_index.core import (
PromptTemplate,
SQLDatabase,
StorageContext,
VectorStoreIndex,
load_index_from_storage,
)
from llama_index.core.llms import ChatResponse
from llama_index.core.objects import ObjectIndex, SQLTableNodeMapping, SQLTableSchema
from llama_index.core.prompts.prompt_type import PromptType
from llama_index.core.retrievers import SQLRetriever
from llama_index.core.schema import TextNode
from llama_index.llms.openai import OpenAI
from sqlalchemy import create_engine, text
from utils import env
# {{docs-fragment index_tables}}
@flyte.trace
async def index_table(table_name: str, table_index_dir: str, database_uri: str) -> str:
"""Index a single table into vector store."""
path = f"{table_index_dir}/{table_name}"
engine = create_engine(database_uri)
def _fetch_rows():
with engine.connect() as conn:
cursor = conn.execute(text(f'SELECT * FROM "{table_name}"'))
return cursor.fetchall()
result = await asyncio.to_thread(_fetch_rows)
nodes = [TextNode(text=str(tuple(row))) for row in result]
index = VectorStoreIndex(nodes)
index.set_index_id("vector_index")
index.storage_context.persist(path)
return path
@env.task
async def index_all_tables(db_file: File) -> Dir:
"""Index all tables concurrently."""
table_index_dir = "table_indices"
Path(table_index_dir).mkdir(exist_ok=True)
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
tasks = [
index_table(t, table_index_dir, "sqlite:///local_db.sqlite")
for t in sql_database.get_usable_table_names()
]
await asyncio.gather(*tasks)
remote_dir = await Dir.from_local(table_index_dir)
return remote_dir
# {{/docs-fragment index_tables}}
@flyte.trace
async def get_table_schema_context(
table_schema_obj: SQLTableSchema,
database_uri: str,
) -> str:
"""Retrieve schema + optional description context for a single table."""
engine = create_engine(database_uri)
sql_database = SQLDatabase(engine)
table_info = sql_database.get_single_table_info(table_schema_obj.table_name)
if table_schema_obj.context_str:
table_info += f" The table description is: {table_schema_obj.context_str}"
return table_info
@flyte.trace
async def get_table_row_context(
table_schema_obj: SQLTableSchema,
local_vector_index_dir: str,
query: str,
) -> str:
"""Retrieve row-level context examples using vector search."""
storage_context = StorageContext.from_defaults(
persist_dir=str(f"{local_vector_index_dir}/{table_schema_obj.table_name}")
)
vector_index = load_index_from_storage(storage_context, index_id="vector_index")
vector_retriever = vector_index.as_retriever(similarity_top_k=2)
relevant_nodes = vector_retriever.retrieve(query)
if not relevant_nodes:
return ""
row_context = "\nHere are some relevant example rows (values in the same order as columns above)\n"
for node in relevant_nodes:
row_context += str(node.get_content()) + "\n"
return row_context
async def process_table(
table_schema_obj: SQLTableSchema,
database_uri: str,
local_vector_index_dir: str,
query: str,
) -> str:
"""Combine schema + row context for one table."""
table_info = await get_table_schema_context(table_schema_obj, database_uri)
row_context = await get_table_row_context(
table_schema_obj, local_vector_index_dir, query
)
full_context = table_info
if row_context:
full_context += "\n" + row_context
print(f"Table Info: {full_context}")
return full_context
async def get_table_context_and_rows_str(
query: str,
database_uri: str,
table_schema_objs: list[SQLTableSchema],
vector_index_dir: Dir,
):
"""Get combined schema + row context for all tables."""
local_vector_index_dir = await vector_index_dir.download()
# run per-table work concurrently
context_strs = await asyncio.gather(
*[
process_table(t, database_uri, local_vector_index_dir, query)
for t in table_schema_objs
]
)
return "\n\n".join(context_strs)
# {{docs-fragment retrieve_tables}}
@env.task
async def retrieve_tables(
query: str,
table_infos: list[TableInfo | None],
db_file: File,
vector_index_dir: Dir,
) -> str:
"""Retrieve relevant tables and return schema context string."""
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
table_node_mapping = SQLTableNodeMapping(sql_database)
table_schema_objs = [
SQLTableSchema(table_name=t.table_name, context_str=t.table_summary)
for t in table_infos
if t is not None
]
obj_index = ObjectIndex.from_objects(
table_schema_objs,
table_node_mapping,
VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)
retrieved_schemas = obj_retriever.retrieve(query)
return await get_table_context_and_rows_str(
query, "sqlite:///local_db.sqlite", retrieved_schemas, vector_index_dir
)
# {{/docs-fragment retrieve_tables}}
def parse_response_to_sql(chat_response: ChatResponse) -> str:
"""Extract SQL query from LLM response."""
response = chat_response.message.content
sql_query_start = response.find("SQLQuery:")
if sql_query_start != -1:
response = response[sql_query_start:]
if response.startswith("SQLQuery:"):
response = response[len("SQLQuery:") :]
sql_result_start = response.find("SQLResult:")
if sql_result_start != -1:
response = response[:sql_result_start]
return response.strip().strip("```").strip()
# {{docs-fragment sql_and_response}}
@env.task
async def generate_sql(query: str, table_context: str, model: str, prompt: str) -> str:
"""Generate SQL query from natural language question and table context."""
llm = OpenAI(model=model)
fmt_messages = (
PromptTemplate(
prompt,
prompt_type=PromptType.TEXT_TO_SQL,
)
.partial_format(dialect="sqlite")
.format_messages(query_str=query, schema=table_context)
)
chat_response = await llm.achat(fmt_messages)
return parse_response_to_sql(chat_response)
@env.task
async def generate_response(query: str, sql: str, db_file: File, model: str) -> str:
"""Run SQL query on database and synthesize final response."""
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
sql_retriever = SQLRetriever(sql_database)
retrieved_rows = sql_retriever.retrieve(sql)
response_synthesis_prompt = PromptTemplate(
"Given an input question, synthesize a response from the query results.\n"
"Query: {query_str}\n"
"SQL: {sql_query}\n"
"SQL Response: {context_str}\n"
"Response: "
)
llm = OpenAI(model=model)
fmt_messages = response_synthesis_prompt.format_messages(
sql_query=sql,
context_str=str(retrieved_rows),
query_str=query,
)
chat_response = await llm.achat(fmt_messages)
return chat_response.message.content
# {{/docs-fragment sql_and_response}}
# {{docs-fragment text_to_sql}}
@env.task
async def text_to_sql(
system_prompt: str = (
"Given an input question, first create a syntactically correct {dialect} "
"query to run, then look at the results of the query and return the answer. "
"You can order the results by a relevant column to return the most "
"interesting examples in the database.\n\n"
"Never query for all the columns from a specific table, only ask for a "
"few relevant columns given the question.\n\n"
"Pay attention to use only the column names that you can see in the schema "
"description. "
"Be careful to not query for columns that do not exist. "
"Pay attention to which column is in which table. "
"Also, qualify column names with the table name when needed. "
"You are required to use the following format, each taking one line:\n\n"
"Question: Question here\n"
"SQLQuery: SQL Query to run\n"
"SQLResult: Result of the SQLQuery\n"
"Answer: Final answer here\n\n"
"Only use tables listed below.\n"
"{schema}\n\n"
"Question: {query_str}\n"
"SQLQuery: "
),
query: str = "What was the year that The Notorious BIG was signed to Bad Boy?",
model: str = "gpt-4o-mini",
) -> str:
db_file, table_infos = await data_ingestion()
vector_index_dir = await index_all_tables(db_file)
table_context = await retrieve_tables(query, table_infos, db_file, vector_index_dir)
sql = await generate_sql(query, table_context, model, system_prompt)
return await generate_response(query, sql, db_file, model)
# {{/docs-fragment text_to_sql}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(text_to_sql)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/text_to_sql.py*
The retriever selects tables via semantic similarity, then attaches their schema and example rows. This context grounds the model's SQL generation in the database's actual structure and content.
### SQL generation and response synthesis
Finally, we generate SQL queries and produce natural language answers.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "llama-index-core>=0.11.0",
# "llama-index-llms-openai>=0.2.0",
# "sqlalchemy>=2.0.0",
# "pandas>=2.0.0",
# "requests>=2.25.0",
# "pydantic>=2.0.0",
# ]
# main = "text_to_sql"
# params = ""
# ///
import asyncio
from pathlib import Path
import flyte
from data_ingestion import TableInfo, data_ingestion
from flyte.io import Dir, File
from llama_index.core import (
PromptTemplate,
SQLDatabase,
StorageContext,
VectorStoreIndex,
load_index_from_storage,
)
from llama_index.core.llms import ChatResponse
from llama_index.core.objects import ObjectIndex, SQLTableNodeMapping, SQLTableSchema
from llama_index.core.prompts.prompt_type import PromptType
from llama_index.core.retrievers import SQLRetriever
from llama_index.core.schema import TextNode
from llama_index.llms.openai import OpenAI
from sqlalchemy import create_engine, text
from utils import env
# {{docs-fragment index_tables}}
@flyte.trace
async def index_table(table_name: str, table_index_dir: str, database_uri: str) -> str:
"""Index a single table into vector store."""
path = f"{table_index_dir}/{table_name}"
engine = create_engine(database_uri)
def _fetch_rows():
with engine.connect() as conn:
cursor = conn.execute(text(f'SELECT * FROM "{table_name}"'))
return cursor.fetchall()
result = await asyncio.to_thread(_fetch_rows)
nodes = [TextNode(text=str(tuple(row))) for row in result]
index = VectorStoreIndex(nodes)
index.set_index_id("vector_index")
index.storage_context.persist(path)
return path
@env.task
async def index_all_tables(db_file: File) -> Dir:
"""Index all tables concurrently."""
table_index_dir = "table_indices"
Path(table_index_dir).mkdir(exist_ok=True)
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
tasks = [
index_table(t, table_index_dir, "sqlite:///local_db.sqlite")
for t in sql_database.get_usable_table_names()
]
await asyncio.gather(*tasks)
remote_dir = await Dir.from_local(table_index_dir)
return remote_dir
# {{/docs-fragment index_tables}}
@flyte.trace
async def get_table_schema_context(
table_schema_obj: SQLTableSchema,
database_uri: str,
) -> str:
"""Retrieve schema + optional description context for a single table."""
engine = create_engine(database_uri)
sql_database = SQLDatabase(engine)
table_info = sql_database.get_single_table_info(table_schema_obj.table_name)
if table_schema_obj.context_str:
table_info += f" The table description is: {table_schema_obj.context_str}"
return table_info
@flyte.trace
async def get_table_row_context(
table_schema_obj: SQLTableSchema,
local_vector_index_dir: str,
query: str,
) -> str:
"""Retrieve row-level context examples using vector search."""
storage_context = StorageContext.from_defaults(
persist_dir=str(f"{local_vector_index_dir}/{table_schema_obj.table_name}")
)
vector_index = load_index_from_storage(storage_context, index_id="vector_index")
vector_retriever = vector_index.as_retriever(similarity_top_k=2)
relevant_nodes = vector_retriever.retrieve(query)
if not relevant_nodes:
return ""
row_context = "\nHere are some relevant example rows (values in the same order as columns above)\n"
for node in relevant_nodes:
row_context += str(node.get_content()) + "\n"
return row_context
async def process_table(
table_schema_obj: SQLTableSchema,
database_uri: str,
local_vector_index_dir: str,
query: str,
) -> str:
"""Combine schema + row context for one table."""
table_info = await get_table_schema_context(table_schema_obj, database_uri)
row_context = await get_table_row_context(
table_schema_obj, local_vector_index_dir, query
)
full_context = table_info
if row_context:
full_context += "\n" + row_context
print(f"Table Info: {full_context}")
return full_context
async def get_table_context_and_rows_str(
query: str,
database_uri: str,
table_schema_objs: list[SQLTableSchema],
vector_index_dir: Dir,
):
"""Get combined schema + row context for all tables."""
local_vector_index_dir = await vector_index_dir.download()
# run per-table work concurrently
context_strs = await asyncio.gather(
*[
process_table(t, database_uri, local_vector_index_dir, query)
for t in table_schema_objs
]
)
return "\n\n".join(context_strs)
# {{docs-fragment retrieve_tables}}
@env.task
async def retrieve_tables(
query: str,
table_infos: list[TableInfo | None],
db_file: File,
vector_index_dir: Dir,
) -> str:
"""Retrieve relevant tables and return schema context string."""
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
table_node_mapping = SQLTableNodeMapping(sql_database)
table_schema_objs = [
SQLTableSchema(table_name=t.table_name, context_str=t.table_summary)
for t in table_infos
if t is not None
]
obj_index = ObjectIndex.from_objects(
table_schema_objs,
table_node_mapping,
VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)
retrieved_schemas = obj_retriever.retrieve(query)
return await get_table_context_and_rows_str(
query, "sqlite:///local_db.sqlite", retrieved_schemas, vector_index_dir
)
# {{/docs-fragment retrieve_tables}}
def parse_response_to_sql(chat_response: ChatResponse) -> str:
"""Extract SQL query from LLM response."""
response = chat_response.message.content
sql_query_start = response.find("SQLQuery:")
if sql_query_start != -1:
response = response[sql_query_start:]
if response.startswith("SQLQuery:"):
response = response[len("SQLQuery:") :]
sql_result_start = response.find("SQLResult:")
if sql_result_start != -1:
response = response[:sql_result_start]
return response.strip().strip("```").strip()
# {{docs-fragment sql_and_response}}
@env.task
async def generate_sql(query: str, table_context: str, model: str, prompt: str) -> str:
"""Generate SQL query from natural language question and table context."""
llm = OpenAI(model=model)
fmt_messages = (
PromptTemplate(
prompt,
prompt_type=PromptType.TEXT_TO_SQL,
)
.partial_format(dialect="sqlite")
.format_messages(query_str=query, schema=table_context)
)
chat_response = await llm.achat(fmt_messages)
return parse_response_to_sql(chat_response)
@env.task
async def generate_response(query: str, sql: str, db_file: File, model: str) -> str:
"""Run SQL query on database and synthesize final response."""
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
sql_retriever = SQLRetriever(sql_database)
retrieved_rows = sql_retriever.retrieve(sql)
response_synthesis_prompt = PromptTemplate(
"Given an input question, synthesize a response from the query results.\n"
"Query: {query_str}\n"
"SQL: {sql_query}\n"
"SQL Response: {context_str}\n"
"Response: "
)
llm = OpenAI(model=model)
fmt_messages = response_synthesis_prompt.format_messages(
sql_query=sql,
context_str=str(retrieved_rows),
query_str=query,
)
chat_response = await llm.achat(fmt_messages)
return chat_response.message.content
# {{/docs-fragment sql_and_response}}
# {{docs-fragment text_to_sql}}
@env.task
async def text_to_sql(
system_prompt: str = (
"Given an input question, first create a syntactically correct {dialect} "
"query to run, then look at the results of the query and return the answer. "
"You can order the results by a relevant column to return the most "
"interesting examples in the database.\n\n"
"Never query for all the columns from a specific table, only ask for a "
"few relevant columns given the question.\n\n"
"Pay attention to use only the column names that you can see in the schema "
"description. "
"Be careful to not query for columns that do not exist. "
"Pay attention to which column is in which table. "
"Also, qualify column names with the table name when needed. "
"You are required to use the following format, each taking one line:\n\n"
"Question: Question here\n"
"SQLQuery: SQL Query to run\n"
"SQLResult: Result of the SQLQuery\n"
"Answer: Final answer here\n\n"
"Only use tables listed below.\n"
"{schema}\n\n"
"Question: {query_str}\n"
"SQLQuery: "
),
query: str = "What was the year that The Notorious BIG was signed to Bad Boy?",
model: str = "gpt-4o-mini",
) -> str:
db_file, table_infos = await data_ingestion()
vector_index_dir = await index_all_tables(db_file)
table_context = await retrieve_tables(query, table_infos, db_file, vector_index_dir)
sql = await generate_sql(query, table_context, model, system_prompt)
return await generate_response(query, sql, db_file, model)
# {{/docs-fragment text_to_sql}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(text_to_sql)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/text_to_sql.py*
The SQL generation prompt includes schema, example rows, and formatting rules. After execution, the system returns a final answer.
At this point, we have an end-to-end Text-to-SQL pipeline: natural language questions go in, SQL queries run, and answers come back. To make this workflow production-ready, we leveraged several Flyte 2 capabilities. Caching ensures that repeated steps, like table ingestion or vector indexing, don’t need to rerun unnecessarily, saving time and compute. Containerization provides consistent, reproducible execution across environments, making it easier to scale and deploy. Observability features let us track every step of the pipeline, monitor performance, and debug issues quickly.
While the pipeline works end-to-end, to get a pulse on how it performs across multiple prompts and to gradually improve performance, we can start experimenting with prompt tuning.
Two things help make this process meaningful:
- **A clean evaluation dataset** - so we can measure accuracy against trusted ground truth.
- **A systematic evaluation loop** - so we can see whether prompt changes or other adjustments actually help.
With these in place, the next step is to build a "golden" QA dataset that will guide iterative prompt optimization.
## Building the QA dataset
> [!NOTE]
> The WikiTableQuestions dataset already includes question–answer pairs, available in its [GitHub repository](https://github.com/ppasupat/WikiTableQuestions/tree/master/data). To use them for this workflow, you'll need to adapt the data into the required format, but the raw material is there for you to build on.
We generate a dataset of natural language questions paired with executable SQL queries. This dataset acts as the benchmark for prompt tuning and evaluation.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "pandas>=2.0.0",
# "llama-index-core>=0.11.0",
# "llama-index-llms-openai>=0.2.0",
# "pydantic>=2.0.0",
# ]
# main = "build_eval_dataset"
# params = ""
# ///
import sqlite3
import flyte
import pandas as pd
from data_ingestion import data_ingestion
from flyte.io import File
from llama_index.core import PromptTemplate
from llama_index.llms.openai import OpenAI
from utils import env
from pydantic import BaseModel
class QAItem(BaseModel):
question: str
sql: str
class QAList(BaseModel):
items: list[QAItem]
# {{docs-fragment get_and_split_schema}}
@env.task
async def get_and_split_schema(db_file: File, tables_per_chunk: int) -> list[str]:
"""
Download the SQLite DB, extract schema info (columns + sample rows),
then split it into chunks with up to `tables_per_chunk` tables each.
"""
await db_file.download(local_path="local_db.sqlite")
conn = sqlite3.connect("local_db.sqlite")
cursor = conn.cursor()
tables = cursor.execute(
"SELECT name FROM sqlite_master WHERE type='table';"
).fetchall()
schema_blocks = []
for table in tables:
table_name = table[0]
# columns
cursor.execute(f"PRAGMA table_info({table_name});")
columns = [col[1] for col in cursor.fetchall()]
block = f"Table: {table_name}({', '.join(columns)})"
# sample rows
cursor.execute(f"SELECT * FROM {table_name} LIMIT 10;")
rows = cursor.fetchall()
if rows:
block += "\nSample rows:\n"
for row in rows:
block += f"{row}\n"
schema_blocks.append(block)
conn.close()
chunks = []
current_chunk = []
for block in schema_blocks:
current_chunk.append(block)
if len(current_chunk) >= tables_per_chunk:
chunks.append("\n".join(current_chunk))
current_chunk = []
if current_chunk:
chunks.append("\n".join(current_chunk))
return chunks
# {{/docs-fragment get_and_split_schema}}
# {{docs-fragment generate_questions_and_sql}}
@flyte.trace
async def generate_questions_and_sql(
schema: str, num_samples: int, batch_size: int
) -> QAList:
llm = OpenAI(model="gpt-4.1")
prompt_tmpl = PromptTemplate(
"""Prompt: You are helping build a Text-to-SQL dataset.
Here is the database schema:
{schema}
Generate {num} natural language questions a user might ask about this database.
For each question, also provide the correct SQL query.
Reasoning process (you must follow this internally):
- Given an input question, first create a syntactically correct {dialect} SQL query.
- Never use SELECT *; only include the relevant columns.
- Use only columns/tables from the schema. Qualify column names when ambiguous.
- You may order results by a meaningful column to make the query more useful.
- Be careful not to add unnecessary columns.
- Use filters, aggregations, joins, grouping, and subqueries when relevant.
Final Output:
Return only a JSON object with one field:
- "items": a list of {num} objects, each with:
- "question": the natural language question
- "sql": the corresponding SQL query
"""
)
all_items: list[QAItem] = []
# batch generation
for start in range(0, num_samples, batch_size):
current_num = min(batch_size, num_samples - start)
response = llm.structured_predict(
QAList,
prompt_tmpl,
schema=schema,
num=current_num,
)
all_items.extend(response.items)
# deduplicate
seen = set()
unique_items: list[QAItem] = []
for item in all_items:
key = (item.question.strip().lower(), item.sql.strip().lower())
if key not in seen:
seen.add(key)
unique_items.append(item)
return QAList(items=unique_items[:num_samples])
# {{/docs-fragment generate_questions_and_sql}}
@flyte.trace
async def llm_validate_batch(pairs: list[dict[str, str]]) -> list[str]:
"""Validate a batch of question/sql/result dicts using one LLM call."""
batch_prompt = """You are validating the correctness of SQL query results against the question.
For each example, answer only "True" (correct) or "False" (incorrect).
Output one answer per line, in the same order as the examples.
---
"""
for i, pair in enumerate(pairs, start=1):
batch_prompt += f"""
Example {i}:
Question:
{pair['question']}
SQL:
{pair['sql']}
Result:
{pair['rows']}
---
"""
llm = OpenAI(model="gpt-4.1")
resp = await llm.acomplete(batch_prompt)
# Expect exactly one True/False per example
results = [
line.strip()
for line in resp.text.splitlines()
if line.strip() in ("True", "False")
]
return results
# {{docs-fragment validate_sql}}
@env.task
async def validate_sql(
db_file: File, question_sql_pairs: QAList, batch_size: int
) -> list[dict[str, str]]:
await db_file.download(local_path="local_db.sqlite")
conn = sqlite3.connect("local_db.sqlite")
cursor = conn.cursor()
qa_data = []
batch = []
for pair in question_sql_pairs.items:
q, sql = pair.question, pair.sql
try:
cursor.execute(sql)
rows = cursor.fetchall()
batch.append({"question": q, "sql": sql, "rows": str(rows)})
# process when batch is full
if len(batch) == batch_size:
results = await llm_validate_batch(batch)
for pair, is_valid in zip(batch, results):
if is_valid == "True":
qa_data.append(
{
"input": pair["question"],
"sql": pair["sql"],
"target": pair["rows"],
}
)
else:
print(f"Filtered out incorrect result for: {pair['question']}")
batch = []
except Exception as e:
print(f"Skipping invalid SQL: {sql} ({e})")
# process leftover batch
if batch:
results = await llm_validate_batch(batch)
for pair, is_valid in zip(batch, results):
if is_valid == "True":
qa_data.append(
{
"input": pair["question"],
"sql": pair["sql"],
"target": pair["rows"],
}
)
else:
print(f"Filtered out incorrect result for: {pair['question']}")
conn.close()
return qa_data
# {{/docs-fragment validate_sql}}
@flyte.trace
async def save_to_csv(qa_data: list[dict]) -> File:
df = pd.DataFrame(qa_data, columns=["input", "target", "sql"])
csv_file = "qa_dataset.csv"
df.to_csv(csv_file, index=False)
return await File.from_local(csv_file)
# {{docs-fragment build_eval_dataset}}
@env.task
async def build_eval_dataset(
num_samples: int = 300, batch_size: int = 30, tables_per_chunk: int = 3
) -> File:
db_file, _ = await data_ingestion()
schema_chunks = await get_and_split_schema(db_file, tables_per_chunk)
per_chunk_samples = max(1, num_samples // len(schema_chunks))
final_qa_data = []
for chunk in schema_chunks:
qa_list = await generate_questions_and_sql(
schema=chunk,
num_samples=per_chunk_samples,
batch_size=batch_size,
)
qa_data = await validate_sql(db_file, qa_list, batch_size)
final_qa_data.extend(qa_data)
csv_file = await save_to_csv(final_qa_data)
return csv_file
# {{/docs-fragment build_eval_dataset}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(build_eval_dataset)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/create_qa_dataset.py*
The pipeline does the following:
- Schema extraction – pull full database schemas, including table names, columns, and sample rows.
- Question–SQL generation – use an LLM to produce natural language questions with matching SQL queries.
- Validation – run each query against the database, filter out invalid results, and also remove results that aren't relevant.
- Final export – store the clean, validated pairs in CSV format for downstream use.
### Schema extraction and chunking
We break schemas into smaller chunks to cover all tables evenly. This avoids overfitting to a subset of tables and ensures broad coverage across the dataset.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "pandas>=2.0.0",
# "llama-index-core>=0.11.0",
# "llama-index-llms-openai>=0.2.0",
# "pydantic>=2.0.0",
# ]
# main = "build_eval_dataset"
# params = ""
# ///
import sqlite3
import flyte
import pandas as pd
from data_ingestion import data_ingestion
from flyte.io import File
from llama_index.core import PromptTemplate
from llama_index.llms.openai import OpenAI
from utils import env
from pydantic import BaseModel
class QAItem(BaseModel):
question: str
sql: str
class QAList(BaseModel):
items: list[QAItem]
# {{docs-fragment get_and_split_schema}}
@env.task
async def get_and_split_schema(db_file: File, tables_per_chunk: int) -> list[str]:
"""
Download the SQLite DB, extract schema info (columns + sample rows),
then split it into chunks with up to `tables_per_chunk` tables each.
"""
await db_file.download(local_path="local_db.sqlite")
conn = sqlite3.connect("local_db.sqlite")
cursor = conn.cursor()
tables = cursor.execute(
"SELECT name FROM sqlite_master WHERE type='table';"
).fetchall()
schema_blocks = []
for table in tables:
table_name = table[0]
# columns
cursor.execute(f"PRAGMA table_info({table_name});")
columns = [col[1] for col in cursor.fetchall()]
block = f"Table: {table_name}({', '.join(columns)})"
# sample rows
cursor.execute(f"SELECT * FROM {table_name} LIMIT 10;")
rows = cursor.fetchall()
if rows:
block += "\nSample rows:\n"
for row in rows:
block += f"{row}\n"
schema_blocks.append(block)
conn.close()
chunks = []
current_chunk = []
for block in schema_blocks:
current_chunk.append(block)
if len(current_chunk) >= tables_per_chunk:
chunks.append("\n".join(current_chunk))
current_chunk = []
if current_chunk:
chunks.append("\n".join(current_chunk))
return chunks
# {{/docs-fragment get_and_split_schema}}
# {{docs-fragment generate_questions_and_sql}}
@flyte.trace
async def generate_questions_and_sql(
schema: str, num_samples: int, batch_size: int
) -> QAList:
llm = OpenAI(model="gpt-4.1")
prompt_tmpl = PromptTemplate(
"""Prompt: You are helping build a Text-to-SQL dataset.
Here is the database schema:
{schema}
Generate {num} natural language questions a user might ask about this database.
For each question, also provide the correct SQL query.
Reasoning process (you must follow this internally):
- Given an input question, first create a syntactically correct {dialect} SQL query.
- Never use SELECT *; only include the relevant columns.
- Use only columns/tables from the schema. Qualify column names when ambiguous.
- You may order results by a meaningful column to make the query more useful.
- Be careful not to add unnecessary columns.
- Use filters, aggregations, joins, grouping, and subqueries when relevant.
Final Output:
Return only a JSON object with one field:
- "items": a list of {num} objects, each with:
- "question": the natural language question
- "sql": the corresponding SQL query
"""
)
all_items: list[QAItem] = []
# batch generation
for start in range(0, num_samples, batch_size):
current_num = min(batch_size, num_samples - start)
response = llm.structured_predict(
QAList,
prompt_tmpl,
schema=schema,
num=current_num,
)
all_items.extend(response.items)
# deduplicate
seen = set()
unique_items: list[QAItem] = []
for item in all_items:
key = (item.question.strip().lower(), item.sql.strip().lower())
if key not in seen:
seen.add(key)
unique_items.append(item)
return QAList(items=unique_items[:num_samples])
# {{/docs-fragment generate_questions_and_sql}}
@flyte.trace
async def llm_validate_batch(pairs: list[dict[str, str]]) -> list[str]:
"""Validate a batch of question/sql/result dicts using one LLM call."""
batch_prompt = """You are validating the correctness of SQL query results against the question.
For each example, answer only "True" (correct) or "False" (incorrect).
Output one answer per line, in the same order as the examples.
---
"""
for i, pair in enumerate(pairs, start=1):
batch_prompt += f"""
Example {i}:
Question:
{pair['question']}
SQL:
{pair['sql']}
Result:
{pair['rows']}
---
"""
llm = OpenAI(model="gpt-4.1")
resp = await llm.acomplete(batch_prompt)
# Expect exactly one True/False per example
results = [
line.strip()
for line in resp.text.splitlines()
if line.strip() in ("True", "False")
]
return results
# {{docs-fragment validate_sql}}
@env.task
async def validate_sql(
db_file: File, question_sql_pairs: QAList, batch_size: int
) -> list[dict[str, str]]:
await db_file.download(local_path="local_db.sqlite")
conn = sqlite3.connect("local_db.sqlite")
cursor = conn.cursor()
qa_data = []
batch = []
for pair in question_sql_pairs.items:
q, sql = pair.question, pair.sql
try:
cursor.execute(sql)
rows = cursor.fetchall()
batch.append({"question": q, "sql": sql, "rows": str(rows)})
# process when batch is full
if len(batch) == batch_size:
results = await llm_validate_batch(batch)
for pair, is_valid in zip(batch, results):
if is_valid == "True":
qa_data.append(
{
"input": pair["question"],
"sql": pair["sql"],
"target": pair["rows"],
}
)
else:
print(f"Filtered out incorrect result for: {pair['question']}")
batch = []
except Exception as e:
print(f"Skipping invalid SQL: {sql} ({e})")
# process leftover batch
if batch:
results = await llm_validate_batch(batch)
for pair, is_valid in zip(batch, results):
if is_valid == "True":
qa_data.append(
{
"input": pair["question"],
"sql": pair["sql"],
"target": pair["rows"],
}
)
else:
print(f"Filtered out incorrect result for: {pair['question']}")
conn.close()
return qa_data
# {{/docs-fragment validate_sql}}
@flyte.trace
async def save_to_csv(qa_data: list[dict]) -> File:
df = pd.DataFrame(qa_data, columns=["input", "target", "sql"])
csv_file = "qa_dataset.csv"
df.to_csv(csv_file, index=False)
return await File.from_local(csv_file)
# {{docs-fragment build_eval_dataset}}
@env.task
async def build_eval_dataset(
num_samples: int = 300, batch_size: int = 30, tables_per_chunk: int = 3
) -> File:
db_file, _ = await data_ingestion()
schema_chunks = await get_and_split_schema(db_file, tables_per_chunk)
per_chunk_samples = max(1, num_samples // len(schema_chunks))
final_qa_data = []
for chunk in schema_chunks:
qa_list = await generate_questions_and_sql(
schema=chunk,
num_samples=per_chunk_samples,
batch_size=batch_size,
)
qa_data = await validate_sql(db_file, qa_list, batch_size)
final_qa_data.extend(qa_data)
csv_file = await save_to_csv(final_qa_data)
return csv_file
# {{/docs-fragment build_eval_dataset}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(build_eval_dataset)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/create_qa_dataset.py*
### Question and SQL generation
Using structured prompts, we ask an LLM to generate realistic questions users might ask, then pair them with syntactically valid SQL queries. Deduplication ensures diversity across queries.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "pandas>=2.0.0",
# "llama-index-core>=0.11.0",
# "llama-index-llms-openai>=0.2.0",
# "pydantic>=2.0.0",
# ]
# main = "build_eval_dataset"
# params = ""
# ///
import sqlite3
import flyte
import pandas as pd
from data_ingestion import data_ingestion
from flyte.io import File
from llama_index.core import PromptTemplate
from llama_index.llms.openai import OpenAI
from utils import env
from pydantic import BaseModel
class QAItem(BaseModel):
question: str
sql: str
class QAList(BaseModel):
items: list[QAItem]
# {{docs-fragment get_and_split_schema}}
@env.task
async def get_and_split_schema(db_file: File, tables_per_chunk: int) -> list[str]:
"""
Download the SQLite DB, extract schema info (columns + sample rows),
then split it into chunks with up to `tables_per_chunk` tables each.
"""
await db_file.download(local_path="local_db.sqlite")
conn = sqlite3.connect("local_db.sqlite")
cursor = conn.cursor()
tables = cursor.execute(
"SELECT name FROM sqlite_master WHERE type='table';"
).fetchall()
schema_blocks = []
for table in tables:
table_name = table[0]
# columns
cursor.execute(f"PRAGMA table_info({table_name});")
columns = [col[1] for col in cursor.fetchall()]
block = f"Table: {table_name}({', '.join(columns)})"
# sample rows
cursor.execute(f"SELECT * FROM {table_name} LIMIT 10;")
rows = cursor.fetchall()
if rows:
block += "\nSample rows:\n"
for row in rows:
block += f"{row}\n"
schema_blocks.append(block)
conn.close()
chunks = []
current_chunk = []
for block in schema_blocks:
current_chunk.append(block)
if len(current_chunk) >= tables_per_chunk:
chunks.append("\n".join(current_chunk))
current_chunk = []
if current_chunk:
chunks.append("\n".join(current_chunk))
return chunks
# {{/docs-fragment get_and_split_schema}}
# {{docs-fragment generate_questions_and_sql}}
@flyte.trace
async def generate_questions_and_sql(
schema: str, num_samples: int, batch_size: int
) -> QAList:
llm = OpenAI(model="gpt-4.1")
prompt_tmpl = PromptTemplate(
"""Prompt: You are helping build a Text-to-SQL dataset.
Here is the database schema:
{schema}
Generate {num} natural language questions a user might ask about this database.
For each question, also provide the correct SQL query.
Reasoning process (you must follow this internally):
- Given an input question, first create a syntactically correct {dialect} SQL query.
- Never use SELECT *; only include the relevant columns.
- Use only columns/tables from the schema. Qualify column names when ambiguous.
- You may order results by a meaningful column to make the query more useful.
- Be careful not to add unnecessary columns.
- Use filters, aggregations, joins, grouping, and subqueries when relevant.
Final Output:
Return only a JSON object with one field:
- "items": a list of {num} objects, each with:
- "question": the natural language question
- "sql": the corresponding SQL query
"""
)
all_items: list[QAItem] = []
# batch generation
for start in range(0, num_samples, batch_size):
current_num = min(batch_size, num_samples - start)
response = llm.structured_predict(
QAList,
prompt_tmpl,
schema=schema,
num=current_num,
)
all_items.extend(response.items)
# deduplicate
seen = set()
unique_items: list[QAItem] = []
for item in all_items:
key = (item.question.strip().lower(), item.sql.strip().lower())
if key not in seen:
seen.add(key)
unique_items.append(item)
return QAList(items=unique_items[:num_samples])
# {{/docs-fragment generate_questions_and_sql}}
@flyte.trace
async def llm_validate_batch(pairs: list[dict[str, str]]) -> list[str]:
"""Validate a batch of question/sql/result dicts using one LLM call."""
batch_prompt = """You are validating the correctness of SQL query results against the question.
For each example, answer only "True" (correct) or "False" (incorrect).
Output one answer per line, in the same order as the examples.
---
"""
for i, pair in enumerate(pairs, start=1):
batch_prompt += f"""
Example {i}:
Question:
{pair['question']}
SQL:
{pair['sql']}
Result:
{pair['rows']}
---
"""
llm = OpenAI(model="gpt-4.1")
resp = await llm.acomplete(batch_prompt)
# Expect exactly one True/False per example
results = [
line.strip()
for line in resp.text.splitlines()
if line.strip() in ("True", "False")
]
return results
# {{docs-fragment validate_sql}}
@env.task
async def validate_sql(
db_file: File, question_sql_pairs: QAList, batch_size: int
) -> list[dict[str, str]]:
await db_file.download(local_path="local_db.sqlite")
conn = sqlite3.connect("local_db.sqlite")
cursor = conn.cursor()
qa_data = []
batch = []
for pair in question_sql_pairs.items:
q, sql = pair.question, pair.sql
try:
cursor.execute(sql)
rows = cursor.fetchall()
batch.append({"question": q, "sql": sql, "rows": str(rows)})
# process when batch is full
if len(batch) == batch_size:
results = await llm_validate_batch(batch)
for pair, is_valid in zip(batch, results):
if is_valid == "True":
qa_data.append(
{
"input": pair["question"],
"sql": pair["sql"],
"target": pair["rows"],
}
)
else:
print(f"Filtered out incorrect result for: {pair['question']}")
batch = []
except Exception as e:
print(f"Skipping invalid SQL: {sql} ({e})")
# process leftover batch
if batch:
results = await llm_validate_batch(batch)
for pair, is_valid in zip(batch, results):
if is_valid == "True":
qa_data.append(
{
"input": pair["question"],
"sql": pair["sql"],
"target": pair["rows"],
}
)
else:
print(f"Filtered out incorrect result for: {pair['question']}")
conn.close()
return qa_data
# {{/docs-fragment validate_sql}}
@flyte.trace
async def save_to_csv(qa_data: list[dict]) -> File:
df = pd.DataFrame(qa_data, columns=["input", "target", "sql"])
csv_file = "qa_dataset.csv"
df.to_csv(csv_file, index=False)
return await File.from_local(csv_file)
# {{docs-fragment build_eval_dataset}}
@env.task
async def build_eval_dataset(
num_samples: int = 300, batch_size: int = 30, tables_per_chunk: int = 3
) -> File:
db_file, _ = await data_ingestion()
schema_chunks = await get_and_split_schema(db_file, tables_per_chunk)
per_chunk_samples = max(1, num_samples // len(schema_chunks))
final_qa_data = []
for chunk in schema_chunks:
qa_list = await generate_questions_and_sql(
schema=chunk,
num_samples=per_chunk_samples,
batch_size=batch_size,
)
qa_data = await validate_sql(db_file, qa_list, batch_size)
final_qa_data.extend(qa_data)
csv_file = await save_to_csv(final_qa_data)
return csv_file
# {{/docs-fragment build_eval_dataset}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(build_eval_dataset)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/create_qa_dataset.py*
### Validation and quality control
Each generated SQL query runs against the database, and another LLM double-checks that the result matches the intent of the natural language question.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "pandas>=2.0.0",
# "llama-index-core>=0.11.0",
# "llama-index-llms-openai>=0.2.0",
# "pydantic>=2.0.0",
# ]
# main = "build_eval_dataset"
# params = ""
# ///
import sqlite3
import flyte
import pandas as pd
from data_ingestion import data_ingestion
from flyte.io import File
from llama_index.core import PromptTemplate
from llama_index.llms.openai import OpenAI
from utils import env
from pydantic import BaseModel
class QAItem(BaseModel):
question: str
sql: str
class QAList(BaseModel):
items: list[QAItem]
# {{docs-fragment get_and_split_schema}}
@env.task
async def get_and_split_schema(db_file: File, tables_per_chunk: int) -> list[str]:
"""
Download the SQLite DB, extract schema info (columns + sample rows),
then split it into chunks with up to `tables_per_chunk` tables each.
"""
await db_file.download(local_path="local_db.sqlite")
conn = sqlite3.connect("local_db.sqlite")
cursor = conn.cursor()
tables = cursor.execute(
"SELECT name FROM sqlite_master WHERE type='table';"
).fetchall()
schema_blocks = []
for table in tables:
table_name = table[0]
# columns
cursor.execute(f"PRAGMA table_info({table_name});")
columns = [col[1] for col in cursor.fetchall()]
block = f"Table: {table_name}({', '.join(columns)})"
# sample rows
cursor.execute(f"SELECT * FROM {table_name} LIMIT 10;")
rows = cursor.fetchall()
if rows:
block += "\nSample rows:\n"
for row in rows:
block += f"{row}\n"
schema_blocks.append(block)
conn.close()
chunks = []
current_chunk = []
for block in schema_blocks:
current_chunk.append(block)
if len(current_chunk) >= tables_per_chunk:
chunks.append("\n".join(current_chunk))
current_chunk = []
if current_chunk:
chunks.append("\n".join(current_chunk))
return chunks
# {{/docs-fragment get_and_split_schema}}
# {{docs-fragment generate_questions_and_sql}}
@flyte.trace
async def generate_questions_and_sql(
schema: str, num_samples: int, batch_size: int
) -> QAList:
llm = OpenAI(model="gpt-4.1")
prompt_tmpl = PromptTemplate(
"""Prompt: You are helping build a Text-to-SQL dataset.
Here is the database schema:
{schema}
Generate {num} natural language questions a user might ask about this database.
For each question, also provide the correct SQL query.
Reasoning process (you must follow this internally):
- Given an input question, first create a syntactically correct {dialect} SQL query.
- Never use SELECT *; only include the relevant columns.
- Use only columns/tables from the schema. Qualify column names when ambiguous.
- You may order results by a meaningful column to make the query more useful.
- Be careful not to add unnecessary columns.
- Use filters, aggregations, joins, grouping, and subqueries when relevant.
Final Output:
Return only a JSON object with one field:
- "items": a list of {num} objects, each with:
- "question": the natural language question
- "sql": the corresponding SQL query
"""
)
all_items: list[QAItem] = []
# batch generation
for start in range(0, num_samples, batch_size):
current_num = min(batch_size, num_samples - start)
response = llm.structured_predict(
QAList,
prompt_tmpl,
schema=schema,
num=current_num,
)
all_items.extend(response.items)
# deduplicate
seen = set()
unique_items: list[QAItem] = []
for item in all_items:
key = (item.question.strip().lower(), item.sql.strip().lower())
if key not in seen:
seen.add(key)
unique_items.append(item)
return QAList(items=unique_items[:num_samples])
# {{/docs-fragment generate_questions_and_sql}}
@flyte.trace
async def llm_validate_batch(pairs: list[dict[str, str]]) -> list[str]:
"""Validate a batch of question/sql/result dicts using one LLM call."""
batch_prompt = """You are validating the correctness of SQL query results against the question.
For each example, answer only "True" (correct) or "False" (incorrect).
Output one answer per line, in the same order as the examples.
---
"""
for i, pair in enumerate(pairs, start=1):
batch_prompt += f"""
Example {i}:
Question:
{pair['question']}
SQL:
{pair['sql']}
Result:
{pair['rows']}
---
"""
llm = OpenAI(model="gpt-4.1")
resp = await llm.acomplete(batch_prompt)
# Expect exactly one True/False per example
results = [
line.strip()
for line in resp.text.splitlines()
if line.strip() in ("True", "False")
]
return results
# {{docs-fragment validate_sql}}
@env.task
async def validate_sql(
db_file: File, question_sql_pairs: QAList, batch_size: int
) -> list[dict[str, str]]:
await db_file.download(local_path="local_db.sqlite")
conn = sqlite3.connect("local_db.sqlite")
cursor = conn.cursor()
qa_data = []
batch = []
for pair in question_sql_pairs.items:
q, sql = pair.question, pair.sql
try:
cursor.execute(sql)
rows = cursor.fetchall()
batch.append({"question": q, "sql": sql, "rows": str(rows)})
# process when batch is full
if len(batch) == batch_size:
results = await llm_validate_batch(batch)
for pair, is_valid in zip(batch, results):
if is_valid == "True":
qa_data.append(
{
"input": pair["question"],
"sql": pair["sql"],
"target": pair["rows"],
}
)
else:
print(f"Filtered out incorrect result for: {pair['question']}")
batch = []
except Exception as e:
print(f"Skipping invalid SQL: {sql} ({e})")
# process leftover batch
if batch:
results = await llm_validate_batch(batch)
for pair, is_valid in zip(batch, results):
if is_valid == "True":
qa_data.append(
{
"input": pair["question"],
"sql": pair["sql"],
"target": pair["rows"],
}
)
else:
print(f"Filtered out incorrect result for: {pair['question']}")
conn.close()
return qa_data
# {{/docs-fragment validate_sql}}
@flyte.trace
async def save_to_csv(qa_data: list[dict]) -> File:
df = pd.DataFrame(qa_data, columns=["input", "target", "sql"])
csv_file = "qa_dataset.csv"
df.to_csv(csv_file, index=False)
return await File.from_local(csv_file)
# {{docs-fragment build_eval_dataset}}
@env.task
async def build_eval_dataset(
num_samples: int = 300, batch_size: int = 30, tables_per_chunk: int = 3
) -> File:
db_file, _ = await data_ingestion()
schema_chunks = await get_and_split_schema(db_file, tables_per_chunk)
per_chunk_samples = max(1, num_samples // len(schema_chunks))
final_qa_data = []
for chunk in schema_chunks:
qa_list = await generate_questions_and_sql(
schema=chunk,
num_samples=per_chunk_samples,
batch_size=batch_size,
)
qa_data = await validate_sql(db_file, qa_list, batch_size)
final_qa_data.extend(qa_data)
csv_file = await save_to_csv(final_qa_data)
return csv_file
# {{/docs-fragment build_eval_dataset}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(build_eval_dataset)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/create_qa_dataset.py*
Even with automated checks, human review remains critical. Since this dataset serves as the ground truth, mislabeled pairs can distort evaluation. For production use, always invest in human-in-the-loop review.
Support for human-in-the-loop pipelines is coming soon in Flyte 2!
## Optimizing prompts
With the QA dataset in place, we can turn to prompt optimization. The idea: start from a baseline prompt, generate new variants, and measure whether accuracy improves.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "pandas>=2.0.0",
# "sqlalchemy>=2.0.0",
# "llama-index-core>=0.11.0",
# "llama-index-llms-openai>=0.2.0",
# ]
# main = "auto_prompt_engineering"
# params = ""
# ///
import asyncio
import html
import os
import re
from dataclasses import dataclass
from typing import Optional, Union
import flyte
import flyte.report
import pandas as pd
from data_ingestion import TableInfo
from flyte.io import Dir, File
from llama_index.core import SQLDatabase
from llama_index.core.retrievers import SQLRetriever
from sqlalchemy import create_engine
from text_to_sql import data_ingestion, generate_sql, index_all_tables, retrieve_tables
from utils import env
CSS = """
"""
@env.task
async def data_prep(csv_file: File | str) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Load Q&A data from a public Google Sheet CSV export URL and split into val/test DataFrames.
The sheet should have columns: 'input' and 'target'.
"""
df = pd.read_csv(
await csv_file.download() if isinstance(csv_file, File) else csv_file
)
if "input" not in df.columns or "target" not in df.columns:
raise ValueError("Sheet must contain 'input' and 'target' columns.")
# Shuffle rows
df = df.sample(frac=1, random_state=1234).reset_index(drop=True)
# Val/Test split
df_renamed = df.rename(columns={"input": "question", "target": "answer"})
n = len(df_renamed)
split = n // 2
df_val = df_renamed.iloc[:split]
df_test = df_renamed.iloc[split:]
return df_val, df_test
@dataclass
class ModelConfig:
model_name: str
hosted_model_uri: Optional[str] = None
temperature: float = 0.0
max_tokens: Optional[int] = 1000
timeout: int = 600
prompt: str = ""
@flyte.trace
async def call_model(
model_config: ModelConfig,
messages: list[dict[str, str]],
) -> str:
from litellm import acompletion
response = await acompletion(
model=model_config.model_name,
api_base=model_config.hosted_model_uri,
messages=messages,
temperature=model_config.temperature,
timeout=model_config.timeout,
max_tokens=model_config.max_tokens,
)
return response.choices[0].message["content"]
@flyte.trace
async def generate_response(db_file: File, sql: str) -> str:
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
sql_retriever = SQLRetriever(sql_database)
retrieved_rows = sql_retriever.retrieve(sql)
if retrieved_rows:
# Get the structured result and stringify
return str(retrieved_rows[0].node.metadata["result"])
return ""
async def generate_and_review(
index: int,
question: str,
answer: str,
target_model_config: ModelConfig,
review_model_config: ModelConfig,
db_file: File,
table_infos: list[TableInfo | None],
vector_index_dir: Dir,
) -> dict:
# Generate response from target model
table_context = await retrieve_tables(
question, table_infos, db_file, vector_index_dir
)
sql = await generate_sql(
question,
table_context,
target_model_config.model_name,
target_model_config.prompt,
)
sql = sql.replace("sql\n", "")
try:
response = await generate_response(db_file, sql)
except Exception as e:
print(f"Failed to generate response for question {question}: {e}")
response = None
# Format review prompt with response + answer
review_messages = [
{
"role": "system",
"content": review_model_config.prompt.format(
query_str=question,
response=response,
answer=answer,
),
}
]
verdict = await call_model(review_model_config, review_messages)
# Normalize verdict
verdict_clean = verdict.strip().lower()
if verdict_clean not in {"true", "false"}:
verdict_clean = "not sure"
return {
"index": index,
"model_response": response,
"sql": sql,
"is_correct": verdict_clean == "true",
}
async def run_grouped_task(
i,
index,
question,
answer,
sql,
semaphore,
target_model_config,
review_model_config,
counter,
counter_lock,
db_file,
table_infos,
vector_index_dir,
):
async with semaphore:
with flyte.group(name=f"row-{i}"):
result = await generate_and_review(
index,
question,
answer,
target_model_config,
review_model_config,
db_file,
table_infos,
vector_index_dir,
)
async with counter_lock:
# Update counters
counter["processed"] += 1
if result["is_correct"]:
counter["correct"] += 1
correct_html = "✔ Yes"
else:
correct_html = "✘ No"
# Calculate accuracy
accuracy_pct = (counter["correct"] / counter["processed"]) * 100
# Update chart
await flyte.report.log.aio(
f"",
do_flush=True,
)
# Add row to table
await flyte.report.log.aio(
f"""
""",
do_flush=True,
)
return best_result.prompt, best_result.accuracy
# {{/docs-fragment prompt_optimizer}}
async def _log_prompt_row(prompt: str, accuracy: float):
"""Helper to log a single prompt/accuracy row to Flyte report."""
pct = accuracy * 100
if pct > 80:
color = "linear-gradient(90deg, #4CAF50, #81C784)"
elif pct > 60:
color = "linear-gradient(90deg, #FFC107, #FFD54F)"
else:
color = "linear-gradient(90deg, #F44336, #E57373)"
await flyte.report.log.aio(
f"""
{html.escape(prompt)}
{pct:.1f}%
""",
do_flush=True,
)
# {{docs-fragment auto_prompt_engineering}}
@env.task
async def auto_prompt_engineering(
ground_truth_csv: File | str = "/root/ground_truth.csv",
db_config: DatabaseConfig = DatabaseConfig(
csv_zip_path="https://github.com/ppasupat/WikiTableQuestions/releases/download/v1.0.2/WikiTableQuestions-1.0.2-compact.zip",
search_glob="WikiTableQuestions/csv/200-csv/*.csv",
concurrency=5,
model="gpt-4o-mini",
),
target_model_config: ModelConfig = ModelConfig(
model_name="gpt-4.1-mini",
hosted_model_uri=None,
prompt="""Given an input question, create a syntactically correct {dialect} query to run.
Schema:
{schema}
Question: {query_str}
SQL query to run:
""",
max_tokens=10000,
),
review_model_config: ModelConfig = ModelConfig(
model_name="gpt-4.1",
hosted_model_uri=None,
prompt="""Your job is to determine whether the model's response is correct compared to the ground truth taking into account the context of the question.
Both answers were generated by running SQL queries on the same database.
- If the model's response contains all of the ground truth values, and any additional information is harmless (e.g., extra columns or metadata), output "True".
- If it adds incorrect or unrelated rows, or omits required values, output "False".
Question:
{query_str}
Ground Truth:
{answer}
Model Response:
{response}
""",
),
optimizer_model_config: ModelConfig = ModelConfig(
model_name="gpt-4.1",
hosted_model_uri=None,
temperature=0.7,
max_tokens=None,
prompt="""
I have some prompts along with their corresponding accuracies.
The prompts are arranged in ascending order based on their accuracy, where higher accuracy indicates better quality.
{prompt_scores_str}
Each prompt was used to translate a natural-language question into a SQL query against a provided database schema.
artists(id, name)
albums(id, title, artist_id, release_year)
How many albums did The Beatles release?
SELECT COUNT(*) FROM albums a JOIN artists r ON a.artist_id = r.id WHERE r.name = 'The Beatles';
Write a new prompt that will achieve an accuracy as high as possible and that is different from the old ones.
- It is very important that the new prompt is distinct from ALL the old ones!
- Ensure that you analyse the prompts with a high accuracy and reuse the patterns that worked in the past.
- Ensure that you analyse the prompts with a low accuracy and avoid the patterns that didn't work in the past.
- Think out loud before creating the prompt. Describe what has worked in the past and what hasn't. Only then create the new prompt.
- Use all available information like prompt length, formal/informal use of language, etc. for your analysis.
- Be creative, try out different ways of prompting the model. You may even come up with hypothetical scenarios that might improve the accuracy.
- You are generating a system prompt. Always use three placeholders for each prompt: dialect, schema, query_str.
- Write your new prompt in double square brackets. Use only plain text for the prompt text and do not add any markdown (i.e. no hashtags, backticks, quotes, etc).
""",
),
max_iterations: int = 5,
concurrency: int = 10,
) -> dict[str, Union[str, float]]:
if isinstance(ground_truth_csv, str) and os.path.isfile(ground_truth_csv):
ground_truth_csv = await File.from_local(ground_truth_csv)
df_val, df_test = await data_prep(ground_truth_csv)
best_prompt, val_accuracy = await prompt_optimizer(
df_val,
target_model_config,
review_model_config,
optimizer_model_config,
max_iterations,
concurrency,
db_config,
)
with flyte.group(name="test_data_evaluation"):
baseline_test_accuracy = await evaluate_prompt(
df_test,
target_model_config,
review_model_config,
concurrency,
db_config,
)
target_model_config.prompt = best_prompt
test_accuracy = await evaluate_prompt(
df_test,
target_model_config,
review_model_config,
concurrency,
db_config,
)
return {
"best_prompt": best_prompt,
"validation_accuracy": val_accuracy,
"baseline_test_accuracy": baseline_test_accuracy,
"test_accuracy": test_accuracy,
}
# {{/docs-fragment auto_prompt_engineering}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(auto_prompt_engineering)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/optimizer.py*
### Evaluation pipeline
We evaluate each prompt variant against the golden dataset, split into validation and test sets, and record accuracy metrics in real time.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "pandas>=2.0.0",
# "sqlalchemy>=2.0.0",
# "llama-index-core>=0.11.0",
# "llama-index-llms-openai>=0.2.0",
# ]
# main = "auto_prompt_engineering"
# params = ""
# ///
import asyncio
import html
import os
import re
from dataclasses import dataclass
from typing import Optional, Union
import flyte
import flyte.report
import pandas as pd
from data_ingestion import TableInfo
from flyte.io import Dir, File
from llama_index.core import SQLDatabase
from llama_index.core.retrievers import SQLRetriever
from sqlalchemy import create_engine
from text_to_sql import data_ingestion, generate_sql, index_all_tables, retrieve_tables
from utils import env
CSS = """
"""
@env.task
async def data_prep(csv_file: File | str) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Load Q&A data from a public Google Sheet CSV export URL and split into val/test DataFrames.
The sheet should have columns: 'input' and 'target'.
"""
df = pd.read_csv(
await csv_file.download() if isinstance(csv_file, File) else csv_file
)
if "input" not in df.columns or "target" not in df.columns:
raise ValueError("Sheet must contain 'input' and 'target' columns.")
# Shuffle rows
df = df.sample(frac=1, random_state=1234).reset_index(drop=True)
# Val/Test split
df_renamed = df.rename(columns={"input": "question", "target": "answer"})
n = len(df_renamed)
split = n // 2
df_val = df_renamed.iloc[:split]
df_test = df_renamed.iloc[split:]
return df_val, df_test
@dataclass
class ModelConfig:
model_name: str
hosted_model_uri: Optional[str] = None
temperature: float = 0.0
max_tokens: Optional[int] = 1000
timeout: int = 600
prompt: str = ""
@flyte.trace
async def call_model(
model_config: ModelConfig,
messages: list[dict[str, str]],
) -> str:
from litellm import acompletion
response = await acompletion(
model=model_config.model_name,
api_base=model_config.hosted_model_uri,
messages=messages,
temperature=model_config.temperature,
timeout=model_config.timeout,
max_tokens=model_config.max_tokens,
)
return response.choices[0].message["content"]
@flyte.trace
async def generate_response(db_file: File, sql: str) -> str:
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
sql_retriever = SQLRetriever(sql_database)
retrieved_rows = sql_retriever.retrieve(sql)
if retrieved_rows:
# Get the structured result and stringify
return str(retrieved_rows[0].node.metadata["result"])
return ""
async def generate_and_review(
index: int,
question: str,
answer: str,
target_model_config: ModelConfig,
review_model_config: ModelConfig,
db_file: File,
table_infos: list[TableInfo | None],
vector_index_dir: Dir,
) -> dict:
# Generate response from target model
table_context = await retrieve_tables(
question, table_infos, db_file, vector_index_dir
)
sql = await generate_sql(
question,
table_context,
target_model_config.model_name,
target_model_config.prompt,
)
sql = sql.replace("sql\n", "")
try:
response = await generate_response(db_file, sql)
except Exception as e:
print(f"Failed to generate response for question {question}: {e}")
response = None
# Format review prompt with response + answer
review_messages = [
{
"role": "system",
"content": review_model_config.prompt.format(
query_str=question,
response=response,
answer=answer,
),
}
]
verdict = await call_model(review_model_config, review_messages)
# Normalize verdict
verdict_clean = verdict.strip().lower()
if verdict_clean not in {"true", "false"}:
verdict_clean = "not sure"
return {
"index": index,
"model_response": response,
"sql": sql,
"is_correct": verdict_clean == "true",
}
async def run_grouped_task(
i,
index,
question,
answer,
sql,
semaphore,
target_model_config,
review_model_config,
counter,
counter_lock,
db_file,
table_infos,
vector_index_dir,
):
async with semaphore:
with flyte.group(name=f"row-{i}"):
result = await generate_and_review(
index,
question,
answer,
target_model_config,
review_model_config,
db_file,
table_infos,
vector_index_dir,
)
async with counter_lock:
# Update counters
counter["processed"] += 1
if result["is_correct"]:
counter["correct"] += 1
correct_html = "✔ Yes"
else:
correct_html = "✘ No"
# Calculate accuracy
accuracy_pct = (counter["correct"] / counter["processed"]) * 100
# Update chart
await flyte.report.log.aio(
f"",
do_flush=True,
)
# Add row to table
await flyte.report.log.aio(
f"""
""",
do_flush=True,
)
return best_result.prompt, best_result.accuracy
# {{/docs-fragment prompt_optimizer}}
async def _log_prompt_row(prompt: str, accuracy: float):
"""Helper to log a single prompt/accuracy row to Flyte report."""
pct = accuracy * 100
if pct > 80:
color = "linear-gradient(90deg, #4CAF50, #81C784)"
elif pct > 60:
color = "linear-gradient(90deg, #FFC107, #FFD54F)"
else:
color = "linear-gradient(90deg, #F44336, #E57373)"
await flyte.report.log.aio(
f"""
{html.escape(prompt)}
{pct:.1f}%
""",
do_flush=True,
)
# {{docs-fragment auto_prompt_engineering}}
@env.task
async def auto_prompt_engineering(
ground_truth_csv: File | str = "/root/ground_truth.csv",
db_config: DatabaseConfig = DatabaseConfig(
csv_zip_path="https://github.com/ppasupat/WikiTableQuestions/releases/download/v1.0.2/WikiTableQuestions-1.0.2-compact.zip",
search_glob="WikiTableQuestions/csv/200-csv/*.csv",
concurrency=5,
model="gpt-4o-mini",
),
target_model_config: ModelConfig = ModelConfig(
model_name="gpt-4.1-mini",
hosted_model_uri=None,
prompt="""Given an input question, create a syntactically correct {dialect} query to run.
Schema:
{schema}
Question: {query_str}
SQL query to run:
""",
max_tokens=10000,
),
review_model_config: ModelConfig = ModelConfig(
model_name="gpt-4.1",
hosted_model_uri=None,
prompt="""Your job is to determine whether the model's response is correct compared to the ground truth taking into account the context of the question.
Both answers were generated by running SQL queries on the same database.
- If the model's response contains all of the ground truth values, and any additional information is harmless (e.g., extra columns or metadata), output "True".
- If it adds incorrect or unrelated rows, or omits required values, output "False".
Question:
{query_str}
Ground Truth:
{answer}
Model Response:
{response}
""",
),
optimizer_model_config: ModelConfig = ModelConfig(
model_name="gpt-4.1",
hosted_model_uri=None,
temperature=0.7,
max_tokens=None,
prompt="""
I have some prompts along with their corresponding accuracies.
The prompts are arranged in ascending order based on their accuracy, where higher accuracy indicates better quality.
{prompt_scores_str}
Each prompt was used to translate a natural-language question into a SQL query against a provided database schema.
artists(id, name)
albums(id, title, artist_id, release_year)
How many albums did The Beatles release?
SELECT COUNT(*) FROM albums a JOIN artists r ON a.artist_id = r.id WHERE r.name = 'The Beatles';
Write a new prompt that will achieve an accuracy as high as possible and that is different from the old ones.
- It is very important that the new prompt is distinct from ALL the old ones!
- Ensure that you analyse the prompts with a high accuracy and reuse the patterns that worked in the past.
- Ensure that you analyse the prompts with a low accuracy and avoid the patterns that didn't work in the past.
- Think out loud before creating the prompt. Describe what has worked in the past and what hasn't. Only then create the new prompt.
- Use all available information like prompt length, formal/informal use of language, etc. for your analysis.
- Be creative, try out different ways of prompting the model. You may even come up with hypothetical scenarios that might improve the accuracy.
- You are generating a system prompt. Always use three placeholders for each prompt: dialect, schema, query_str.
- Write your new prompt in double square brackets. Use only plain text for the prompt text and do not add any markdown (i.e. no hashtags, backticks, quotes, etc).
""",
),
max_iterations: int = 5,
concurrency: int = 10,
) -> dict[str, Union[str, float]]:
if isinstance(ground_truth_csv, str) and os.path.isfile(ground_truth_csv):
ground_truth_csv = await File.from_local(ground_truth_csv)
df_val, df_test = await data_prep(ground_truth_csv)
best_prompt, val_accuracy = await prompt_optimizer(
df_val,
target_model_config,
review_model_config,
optimizer_model_config,
max_iterations,
concurrency,
db_config,
)
with flyte.group(name="test_data_evaluation"):
baseline_test_accuracy = await evaluate_prompt(
df_test,
target_model_config,
review_model_config,
concurrency,
db_config,
)
target_model_config.prompt = best_prompt
test_accuracy = await evaluate_prompt(
df_test,
target_model_config,
review_model_config,
concurrency,
db_config,
)
return {
"best_prompt": best_prompt,
"validation_accuracy": val_accuracy,
"baseline_test_accuracy": baseline_test_accuracy,
"test_accuracy": test_accuracy,
}
# {{/docs-fragment auto_prompt_engineering}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(auto_prompt_engineering)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/optimizer.py*
Here's how prompt accuracy evolves over time, as shown in the UI report:
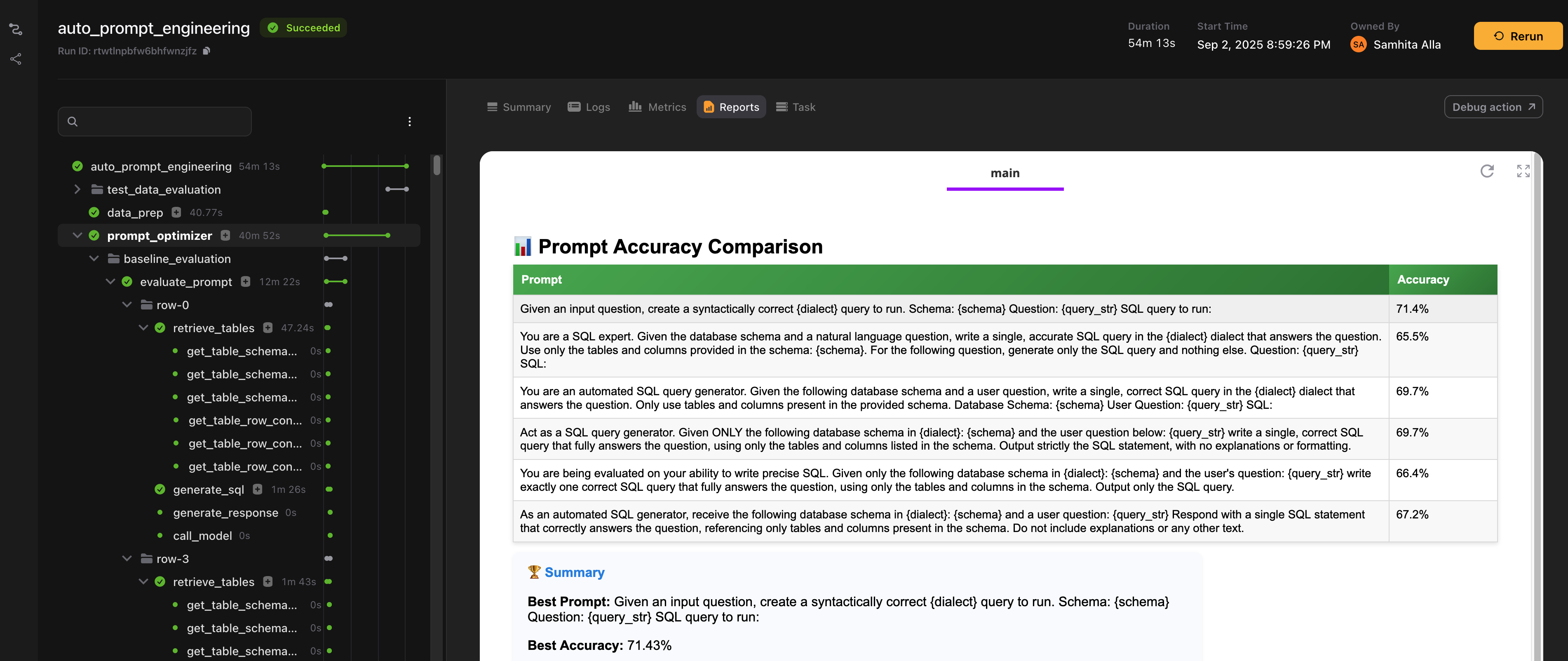
### Iterative optimization
An optimizer LLM proposes new prompts by analyzing patterns in successful and failed generations. Each candidate runs through the evaluation loop, and we select the best performer.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "pandas>=2.0.0",
# "sqlalchemy>=2.0.0",
# "llama-index-core>=0.11.0",
# "llama-index-llms-openai>=0.2.0",
# ]
# main = "auto_prompt_engineering"
# params = ""
# ///
import asyncio
import html
import os
import re
from dataclasses import dataclass
from typing import Optional, Union
import flyte
import flyte.report
import pandas as pd
from data_ingestion import TableInfo
from flyte.io import Dir, File
from llama_index.core import SQLDatabase
from llama_index.core.retrievers import SQLRetriever
from sqlalchemy import create_engine
from text_to_sql import data_ingestion, generate_sql, index_all_tables, retrieve_tables
from utils import env
CSS = """
"""
@env.task
async def data_prep(csv_file: File | str) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Load Q&A data from a public Google Sheet CSV export URL and split into val/test DataFrames.
The sheet should have columns: 'input' and 'target'.
"""
df = pd.read_csv(
await csv_file.download() if isinstance(csv_file, File) else csv_file
)
if "input" not in df.columns or "target" not in df.columns:
raise ValueError("Sheet must contain 'input' and 'target' columns.")
# Shuffle rows
df = df.sample(frac=1, random_state=1234).reset_index(drop=True)
# Val/Test split
df_renamed = df.rename(columns={"input": "question", "target": "answer"})
n = len(df_renamed)
split = n // 2
df_val = df_renamed.iloc[:split]
df_test = df_renamed.iloc[split:]
return df_val, df_test
@dataclass
class ModelConfig:
model_name: str
hosted_model_uri: Optional[str] = None
temperature: float = 0.0
max_tokens: Optional[int] = 1000
timeout: int = 600
prompt: str = ""
@flyte.trace
async def call_model(
model_config: ModelConfig,
messages: list[dict[str, str]],
) -> str:
from litellm import acompletion
response = await acompletion(
model=model_config.model_name,
api_base=model_config.hosted_model_uri,
messages=messages,
temperature=model_config.temperature,
timeout=model_config.timeout,
max_tokens=model_config.max_tokens,
)
return response.choices[0].message["content"]
@flyte.trace
async def generate_response(db_file: File, sql: str) -> str:
await db_file.download(local_path="local_db.sqlite")
engine = create_engine("sqlite:///local_db.sqlite")
sql_database = SQLDatabase(engine)
sql_retriever = SQLRetriever(sql_database)
retrieved_rows = sql_retriever.retrieve(sql)
if retrieved_rows:
# Get the structured result and stringify
return str(retrieved_rows[0].node.metadata["result"])
return ""
async def generate_and_review(
index: int,
question: str,
answer: str,
target_model_config: ModelConfig,
review_model_config: ModelConfig,
db_file: File,
table_infos: list[TableInfo | None],
vector_index_dir: Dir,
) -> dict:
# Generate response from target model
table_context = await retrieve_tables(
question, table_infos, db_file, vector_index_dir
)
sql = await generate_sql(
question,
table_context,
target_model_config.model_name,
target_model_config.prompt,
)
sql = sql.replace("sql\n", "")
try:
response = await generate_response(db_file, sql)
except Exception as e:
print(f"Failed to generate response for question {question}: {e}")
response = None
# Format review prompt with response + answer
review_messages = [
{
"role": "system",
"content": review_model_config.prompt.format(
query_str=question,
response=response,
answer=answer,
),
}
]
verdict = await call_model(review_model_config, review_messages)
# Normalize verdict
verdict_clean = verdict.strip().lower()
if verdict_clean not in {"true", "false"}:
verdict_clean = "not sure"
return {
"index": index,
"model_response": response,
"sql": sql,
"is_correct": verdict_clean == "true",
}
async def run_grouped_task(
i,
index,
question,
answer,
sql,
semaphore,
target_model_config,
review_model_config,
counter,
counter_lock,
db_file,
table_infos,
vector_index_dir,
):
async with semaphore:
with flyte.group(name=f"row-{i}"):
result = await generate_and_review(
index,
question,
answer,
target_model_config,
review_model_config,
db_file,
table_infos,
vector_index_dir,
)
async with counter_lock:
# Update counters
counter["processed"] += 1
if result["is_correct"]:
counter["correct"] += 1
correct_html = "✔ Yes"
else:
correct_html = "✘ No"
# Calculate accuracy
accuracy_pct = (counter["correct"] / counter["processed"]) * 100
# Update chart
await flyte.report.log.aio(
f"",
do_flush=True,
)
# Add row to table
await flyte.report.log.aio(
f"""
""",
do_flush=True,
)
return best_result.prompt, best_result.accuracy
# {{/docs-fragment prompt_optimizer}}
async def _log_prompt_row(prompt: str, accuracy: float):
"""Helper to log a single prompt/accuracy row to Flyte report."""
pct = accuracy * 100
if pct > 80:
color = "linear-gradient(90deg, #4CAF50, #81C784)"
elif pct > 60:
color = "linear-gradient(90deg, #FFC107, #FFD54F)"
else:
color = "linear-gradient(90deg, #F44336, #E57373)"
await flyte.report.log.aio(
f"""
{html.escape(prompt)}
{pct:.1f}%
""",
do_flush=True,
)
# {{docs-fragment auto_prompt_engineering}}
@env.task
async def auto_prompt_engineering(
ground_truth_csv: File | str = "/root/ground_truth.csv",
db_config: DatabaseConfig = DatabaseConfig(
csv_zip_path="https://github.com/ppasupat/WikiTableQuestions/releases/download/v1.0.2/WikiTableQuestions-1.0.2-compact.zip",
search_glob="WikiTableQuestions/csv/200-csv/*.csv",
concurrency=5,
model="gpt-4o-mini",
),
target_model_config: ModelConfig = ModelConfig(
model_name="gpt-4.1-mini",
hosted_model_uri=None,
prompt="""Given an input question, create a syntactically correct {dialect} query to run.
Schema:
{schema}
Question: {query_str}
SQL query to run:
""",
max_tokens=10000,
),
review_model_config: ModelConfig = ModelConfig(
model_name="gpt-4.1",
hosted_model_uri=None,
prompt="""Your job is to determine whether the model's response is correct compared to the ground truth taking into account the context of the question.
Both answers were generated by running SQL queries on the same database.
- If the model's response contains all of the ground truth values, and any additional information is harmless (e.g., extra columns or metadata), output "True".
- If it adds incorrect or unrelated rows, or omits required values, output "False".
Question:
{query_str}
Ground Truth:
{answer}
Model Response:
{response}
""",
),
optimizer_model_config: ModelConfig = ModelConfig(
model_name="gpt-4.1",
hosted_model_uri=None,
temperature=0.7,
max_tokens=None,
prompt="""
I have some prompts along with their corresponding accuracies.
The prompts are arranged in ascending order based on their accuracy, where higher accuracy indicates better quality.
{prompt_scores_str}
Each prompt was used to translate a natural-language question into a SQL query against a provided database schema.
artists(id, name)
albums(id, title, artist_id, release_year)
How many albums did The Beatles release?
SELECT COUNT(*) FROM albums a JOIN artists r ON a.artist_id = r.id WHERE r.name = 'The Beatles';
Write a new prompt that will achieve an accuracy as high as possible and that is different from the old ones.
- It is very important that the new prompt is distinct from ALL the old ones!
- Ensure that you analyse the prompts with a high accuracy and reuse the patterns that worked in the past.
- Ensure that you analyse the prompts with a low accuracy and avoid the patterns that didn't work in the past.
- Think out loud before creating the prompt. Describe what has worked in the past and what hasn't. Only then create the new prompt.
- Use all available information like prompt length, formal/informal use of language, etc. for your analysis.
- Be creative, try out different ways of prompting the model. You may even come up with hypothetical scenarios that might improve the accuracy.
- You are generating a system prompt. Always use three placeholders for each prompt: dialect, schema, query_str.
- Write your new prompt in double square brackets. Use only plain text for the prompt text and do not add any markdown (i.e. no hashtags, backticks, quotes, etc).
""",
),
max_iterations: int = 5,
concurrency: int = 10,
) -> dict[str, Union[str, float]]:
if isinstance(ground_truth_csv, str) and os.path.isfile(ground_truth_csv):
ground_truth_csv = await File.from_local(ground_truth_csv)
df_val, df_test = await data_prep(ground_truth_csv)
best_prompt, val_accuracy = await prompt_optimizer(
df_val,
target_model_config,
review_model_config,
optimizer_model_config,
max_iterations,
concurrency,
db_config,
)
with flyte.group(name="test_data_evaluation"):
baseline_test_accuracy = await evaluate_prompt(
df_test,
target_model_config,
review_model_config,
concurrency,
db_config,
)
target_model_config.prompt = best_prompt
test_accuracy = await evaluate_prompt(
df_test,
target_model_config,
review_model_config,
concurrency,
db_config,
)
return {
"best_prompt": best_prompt,
"validation_accuracy": val_accuracy,
"baseline_test_accuracy": baseline_test_accuracy,
"test_accuracy": test_accuracy,
}
# {{/docs-fragment auto_prompt_engineering}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(auto_prompt_engineering)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/text_to_sql/optimizer.py*
On paper, this creates a continuous improvement cycle: baseline → new variants → measured gains.
## Run it
To create the QA dataset:
```
python create_qa_dataset.py
```
To run the prompt optimization loop:
```
python optimizer.py
```
## What we observed
Prompt optimization didn't consistently lift SQL accuracy in this workflow. Accuracy plateaued near the baseline. But the process surfaced valuable lessons about what matters when building LLM-powered systems on real infrastructure.
- **Schema clarity matters**: CSV ingestion produced tables with overlapping names, creating ambiguity. This showed how schema design and metadata hygiene directly affect downstream evaluation.
- **Ground truth needs trust**: Because the dataset came from LLM outputs, noise remained even after filtering. Human review proved essential. Golden datasets need deliberate curation, not just automation.
- **Optimization needs context**: The optimizer couldn't “see” which examples failed, limiting its ability to improve. Feeding failures directly risks overfitting. A structured way to capture and reuse evaluation signals is the right long-term path.
Sometimes prompt tweaks alone can lift accuracy, but other times the real bottleneck lives in the data, the schema, or the evaluation loop. The lesson isn't "prompt optimization doesn't work", but that its impact depends on the system around it. Accuracy improves most reliably when prompts evolve alongside clean data, trusted evaluation, and observable feedback loops.
## The bigger lesson
Evaluation and optimization aren’t one-off experiments; they’re continuous processes. What makes them sustainable isn't a clever prompt, it’s the platform around it.
Systems succeed when they:
- **Observe** failures with clarity — track exactly what failed and why.
- **Remain durable** across iterations — run pipelines that are stable, reproducible, and comparable over time.
That's where Flyte 2 comes in. Prompt optimization is one lever, but it becomes powerful only when combined with:
- Clean, human-validated evaluation datasets.
- Systematic reporting and feedback loops.
**The real takeaway: improving LLM pipelines isn't about chasing the perfect prompt. It's about designing workflows with observability and durability at the core, so that every experiment compounds into long-term progress.**
---
**Source**: https://github.com/unionai/unionai-docs/blob/main/content/tutorials/text_to_sql/_index.md
**HTML**: https://www.union.ai/docs/v2/union/tutorials/text_to_sql/